# @lc app=leetcode.cn id=61 lang=python3
#
# [61] 旋转链表
#
# @lc code=start
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
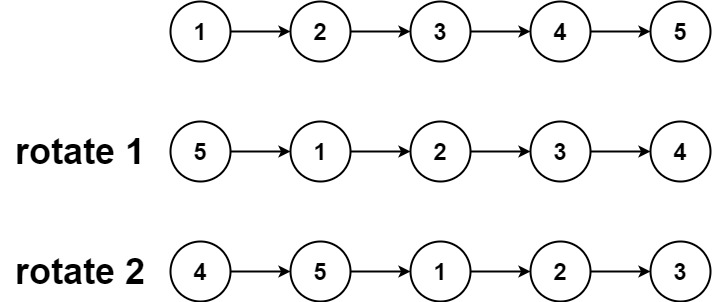
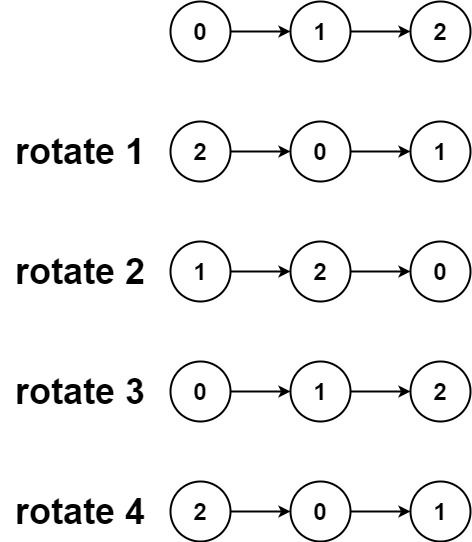
def rotateRight(self, head: Optional[ListNode], k: int) -> Optional[ListNode]:
def lenlink(head):
i=0
while head != None:
head=head.next
i=i+1
return i
lens=lenlink(head)
if lens==0:
return head
k=k%(lens)
newlist=ListNode(0,None)
newcur=newlist
cur1 = head
cur2 = head
for i in range(lens-k):
cur1=cur1.next
#print(cur1.val)
for i in range(lens):
if i < k:
newcur.val= cur1.val
print(newcur.val)
cur1=cur1.next
newcur.next=ListNode(0,None)
newcur=newcur.next
else:
newcur.val= cur2.val
#print(cur2.val)
cur2=cur2.next
if i<lens-1:
newcur.next=ListNode(0,None)
newcur=newcur.next
return newlist
# @lc app=leetcode.cn id=60 lang=python3
#
# [60] 排列序列
#
# @lc code=start
class Solution:
def getPermutation(self, n: int, k: int) -> str:
nums=[i for i in range(1,n+1)]
def subgetPermutation(N,k,nums,str1):
import math
#print(k)
while 1:
if k<0 or len(nums)==1:
str1=str1+str(nums[0])
return str1
x=math.factorial(N-1)
for i in range(1,len(nums)+1):
if i*x>=k:
k=k-(i-1)*x if k-(i-1)*x>0 else k
N=N-1
#print(i,k,N,nums)
str1=str1+str(nums[i-1])
#print(str1)
nums.remove(nums[i-1])
#print(nums)
break
return subgetPermutation(n,k,nums,"")
# @lc code=end
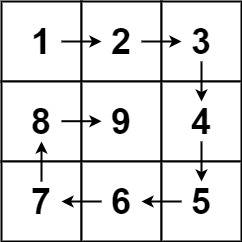
给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。
示例 1:
输入:n = 3
输出:[[1,2,3],[8,9,4],[7,6,5]]
示例 2:
输入:n = 1
输出:[[1]]
提示:
1 <= n <= 20
# @lc app=leetcode.cn id=59 lang=python3
#
# [59] 螺旋矩阵 II
#
# @lc code=start
from calendar import c
class Solution:
def generateMatrix(self, n: int) -> List[List[int]]:
rev=[[0]*n for i in range(n)]
rstart=0
cstart=0
rend=n-1
cend=n-1
mid=1
while cend>=cstart and rstart<=rend:
for l in range(cstart,cend+1):
rev[rstart][l]=mid
mid=mid+1
#rev.extend(matrix[rstart][cstart:cend+1])
for l in range(rstart+1,rend):
rev[l][cend]=mid
mid=mid+1
for l in range(cend,cstart-1,-1):
rev[rend][l]=mid
mid=mid+1
#rev.extend(matrix[rend][cstart:cend+1][::-1])
for l in range(rend-1,rstart,-1):
rev[l][cstart]=mid
mid=mid+1
cend=cend-1
cstart=cstart+1
rstart=rstart+1
rend=rend-1
if n//2!=n/2:
rev[n//2][n//2]=n*n
return rev
# @lc app=leetcode.cn id=55 lang=python3
#
# [55] 跳跃游戏
#
# @lc code=start
class Solution:
def canJump(self, nums: List[int]) -> bool:
re=0
if nums==[0]:
return True
if 0 not in nums:
return True
for i in range(len(nums)-1,-1,-1):
if nums[i]==0:
j=0
re=0
while j<i:
if nums[j]<=(i-j) and i!=len(nums)-1:
j=j+1
continue
elif nums[j]<(i-j) and i==len(nums)-1:
j=j+1
continue
else:
re=1 # True
break
if re==0:
return False
if re == 1:
return True
else:return False
#return False
# @lc app=leetcode.cn id=54 lang=python3
#
# [54] 螺旋矩阵
#
# @lc code=start
class Solution:
def spiralOrder(self, matrix: List[List[int]]) -> List[int]:
rstart=0
cstart=0
rend=len(matrix)-1
cend=len(matrix[0])-1
rev=list()
if cstart==cend:
for i in matrix:
rev.extend(i)
return rev
if rstart==rend:
return matrix[0]
while rstart<rend and cstart<cend :
print(rstart,rend,cstart,cend)
for l in range(cstart,cend+1):
rev.append(matrix[rstart][l])
#rev.extend(matrix[rstart][cstart:cend+1])
for l in range(rstart+1,rend):
rev.append(matrix[l][cend])
for l in range(cend,cstart-1,-1):
rev.append(matrix[rend][l])
#rev.extend(matrix[rend][cstart:cend+1][::-1])
for l in range(rend-1,rstart,-1):
rev.append(matrix[l][cstart])
#print(rev)
cend=cend-1
cstart=cstart+1
rstart=rstart+1
rend=rend-1
if rstart==rend and cstart!=cend:
print("fff")
for l in range(cstart,cend+1):
#print(matrix[rstart][l])
rev.append(matrix[rstart][l])
elif cstart==cend and rstart!=rend:
for l in range(rstart,rend+1):
#print(matrix[l][cstart])
rev.append(matrix[l][cstart])
elif rstart==rend and cstart==cend:
rev.append(matrix[rstart][cstart])
return rev
# @lc code=end