
半监督学习(Semi-Supervised Learning,SSL) 使用标记和未标记的数据来执行有监督的学习或无监督的学习任务。
半监督学习可进一步划分为纯(pure)半监督学习和直推学习(transductive learning)。前者假定训练数据中的未标记样本并非待预测的数据,而后者则假定学习过程中所考虑的未标记样本恰是待预测数据。纯半监督学习是基于“开放世界”假设,希望学得模型能适用于训练过程中未观察到的数据,而直推学习是基于“封闭世界”假设,仅试图对学习过程中观察到的未标记数据进行预测。下图直观的表现出主动学习、纯半监督学习、直推学习的区别:
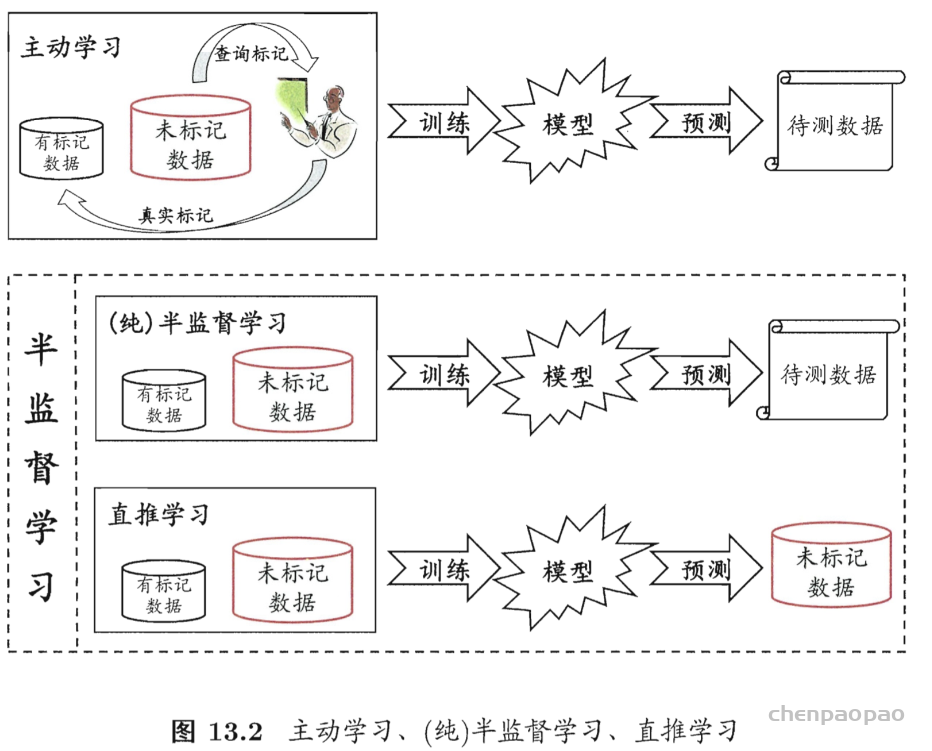
虽然训练数据中含有大量无标签数据,但其实在很多半监督学习算法中用的训练数据还有挺多要求的,一般默认的有:无标签数据一般是有标签数据中的某一个类别的(不要不属于的,也不要属于多个类别的);有标签数据的标签应该都是对的;无标签数据一般是类别平衡的(即每一类的样本数差不多);无标签数据的分布应该和有标签的相同或类似等等。
一般,半监督学习算法可分为:self-training(自训练算法)、Graph-based Semi-supervised Learning(基于图的半监督算法)、Semi-supervised supported vector machine(半监督支持向量机,S3VM)。简单介绍如下:
1.简单自训练(simple self-training):用有标签数据训练一个分类器,然后用这个分类器对无标签数据进行分类,这样就会产生伪标签(pseudo label)或软标签(soft label),挑选你认为分类正确的无标签样本(此处应该有一个挑选准则),把选出来的无标签样本用来训练分类器。
2.协同训练(co-training):其实也是 self-training 的一种,但其思想是好的。假设每个数据可以从不同的角度(view)进行分类,不同角度可以训练出不同的分类器,然后用这些从不同角度训练出来的分类器对无标签样本进行分类,再选出认为可信的无标签样本加入训练集中。由于这些分类器从不同角度训练出来的,可以形成一种互补,而提高分类精度;就如同从不同角度可以更好地理解事物一样。
3.半监督字典学习:其实也是 self-training 的一种,先是用有标签数据作为字典,对无标签数据进行分类,挑选出你认为分类正确的无标签样本,加入字典中(此时的字典就变成了半监督字典了)
4.标签传播算法(Label Propagation Algorithm):是一种基于图的半监督算法,通过构造图结构(数据点为顶点,点之间的相似性为边)来寻找训练数据中有标签数据和无标签数据的关系。是的,只是训练数据中,这是一种直推式的半监督算法,即只对训练集中的无标签数据进行分类,这其实感觉很像一个有监督分类算法…,但其实并不是,因为其标签传播的过程,会流经无标签数据,即有些无标签数据的标签的信息,是从另一些无标签数据中流过来的,这就用到了无标签数据之间的联系
5.半监督支持向量机:监督支持向量机是利用了结构风险最小化来分类的,半监督支持向量机还用上了无标签数据的空间分布信息,即决策超平面应该与无标签数据的分布一致(应该经过无标签数据密度低的地方)(这其实是一种假设,不满足的话这种无标签数据的空间分布信息会误导决策超平面,导致性能比只用有标签数据时还差)
其实,半监督学习的方法大都建立在对数据的某种假设上,只有满足这些假设,半监督算法才能有性能的保证,这也是限制了半监督学习应用的一大障碍。
半监督深度学习
终于来到正题——半监督深度学习,深度学习需要用到大量有标签数据,即使在大数据时代,干净能用的有标签数据也是不多的,由此引发深度学习与半监督学习的结合。
如果要给半监督深度学习下个定义,大概就是,在有标签数据+无标签数据混合成的训练数据中使用的深度学习算法吧…orz.
半监督深度学习算法个人总结为三类:无标签数据预训练网络后有标签数据微调(fine-tune);有标签数据训练网络,利用从网络中得到的深度特征来做半监督算法;让网络 work in semi-supervised fashion。
1.无标签数据预训练,有标签数据微调
对于神经网络来说,一个好的初始化可以使得结果更稳定,迭代次数更少。因此如何利用无标签数据让网络有一个好的初始化就成为一个研究点了。
目前我见过的初始化方式有两种:无监督预训练,和伪有监督预训练
无监督预训练:一是用所有数据逐层重构预训练,对网络的每一层,都做重构自编码,得到参数后用有标签数据微调;二是用所有数据训练重构自编码网络,然后把自编码网络的参数,作为初始参数,用有标签数据微调。
伪有监督预训练:通过某种方式/算法(如半监督算法,聚类算法等),给无标签数据附上伪标签信息,先用这些伪标签信息来预训练网络,然后在用有标签数据来微调。(MAE: mask 编码器)
2.利用从网络得到的深度特征来做半监督算法
神经网络不是需要有标签数据吗?我给你造一些有标签数据出来!这就是第二类的思想了,相当于一种间接的 self-training 吧。一般流程是:
先用有标签数据训练网络(此时网络一般过拟合…),从该网络中提取所有数据的特征,以这些特征来用某种分类算法对无标签数据进行分类,挑选你认为分类正确的无标签数据加入到训练集,再训练网络;如此循环。
由于网络得到新的数据(挑选出来分类后的无标签数据)会更新提升,使得后续提出来的特征更好,后面对无标签数据分类就更精确,挑选后加入到训练集中又继续提升网络,感觉想法很好,但总有哪里不对…orz
个人猜测这个想法不能很好地 work 的原因可能是噪声,你挑选加入到训练无标签数据一般都带有标签噪声(就是某些无标签数据被分类错误),这种噪声会误导网络且被网络学习记忆。
3.让网络 work in semi-supervised fashion
前面的1.和2.虽然是都用了有标签数据和无标签数据,但就神经网络本身而言,其实还是运行在一种有监督的方式上。
哪能不能让深度学习真正地成为一种半监督算法呢,当然是可以啊。譬如下面这些方法:
Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks
这是一篇发表在 ICML 2013 的文章,是一个相当简单的让网络 work in semi-supervised fashion 的方法。就是把网络对无标签数据的预测,作为无标签数据的标签(即 Pseudo label),用来对网络进行训练,其思想就是一种简单自训练。但方法虽然简单,但是效果很好,比单纯用有标签数据有不少的提升。
网络使用的代价函数如下:
L=∑m=1n∑i=1CL(yim,fim)+α(t)∑m=1n′∑i=1CL(y′im,f′im)
代价函数的前面是有标签数据的代价,后面的无标签数据的代价,在无标签数据的代价中,y′无标签数据的 pseudo label,是直接取网络对无标签数据的预测的最大值为标签。
虽然思想简单,但是还是有些东西需要注意的,就是这个α(t),其决定着无标签数据的代价在网络更新的作用,选择合适的α(t)很重要,太大性能退化,太小提升有限。在网络初始时,网络的预测时不太准确的,因此生成的 pseudo label 的准确性也不高。在初始训练时,α(t)要设为 0,然后再慢慢增加,论文中给出其增长函数。在后面的介绍中,有两篇论文都使用了一种高斯型的爬升函数。
感觉这种无标签数据代价达到一种正则化的效果,其减少了网络在有限有标签数据下的过拟合,使得网络泛化地更好。
Semi-Supervised Learning with Ladder Networks
2015年诞生半监督 ladderNet,ladderNet是其他文章中先提出来的想法,但这篇文章使它 work in semi-supervised fashion,而且效果非常好,达到了当时的 state-of-the-art 性能。
ladderNet 是有监督算法和无监督算法的有机结合。前面提到,很多半监督深度学习算法是用无监督预训练这种方式对无标签数据进行利用的,但事实上,这种把无监督学习强加在有监督学习上的方式有缺点:两种学习的目的不一致,其实并不能很好兼容。
无监督预训练一般是用重构样本进行训练,其编码(学习特征)的目的是尽可能地保留样本的信息;而有监督学习是用于分类,希望只保留其本质特征,去除不必要的特征。
ladderNet 通过 skip connection 解决这个问题,通过在每层的编码器和解码器之间添加跳跃连接(skip connection),减轻模型较高层表示细节的压力,使得无监督学习和有监督学习能结合在一起,并在最高层添加分类器,ladderNet 就变身成一个半监督模型。
ladderNet 有机地结合了无监督学习和有监督学习,解决兼容性问题,发展出一个端对端的半监督深度模型。
PS:论文有给出代码
Temporal Ensembling for Semi-supervised Learning
Temporal ensembling 是 Pseudo label 的发展,目的是构造更好的 pseudo label(文中称为 target,我认为是一致的)。
多个独立训练的网络的集成可取得更好的预测,论文扩展了这个观点,提出自集成(self-ensembling),通过同一个模型在不同的迭代期,不同的数据增强和正则化的条件下进行集成,来构造更好的 target。
论文提出了两种不同的实现: Π model 和 temporal ensembling
两个模型的代价函数都是一样的,与 Pseudo Label 的代价函数类似,一个有监督 loss,一个无监督 loss,中间有个权系数函数,与 Pseudo Label 的区别在于,Pseudo Label 的第二项是无标签 loss,是只针对无标签数据的(如果我没理解错..orz),而 Temporal ensembling 的第二项是 无监督 loss,是面向全部数据的。
Π model 的无监督代价是对同一个输入在不同的正则和数据增强条件下的一致性。即要求在不同的条件下,模型的估计要一致,以鼓励网络学习数据内在的不变性。
缺点也是相当明显,每个迭代期要对同一个输入在不同的正则和数据增强的条件下预测两次,相对耗时。还好不同的正则可以使用 dropout 来实现,不然也很麻烦。
temporal ensembling 模型是对每一次迭代期的预测进行移动平均来构造更好的 target,然后用这个 target 来计算无监督 loss,继而更新网络。
缺点也有,记录移动平均的 target 需要较多空间。但 temporal ensembling 的潜力也更大,可以收集更多的信息,如二阶原始矩,可基于这些信息对不同的预测加权等。
Temporal ensembling 还对标签噪声具有鲁棒性,即使有标签数据的标签有误的话,无监督 loss 可以平滑这种错误标签的影响。
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results
Mean Teacher 这篇文章一上来就说“模型成功的关键在于 target 的质量”,一语道破天机啊。而提高 target 的质量的方法目前有两:1.精心选择样本噪声;2. 找到一个更好的 Teacher model。而论文采用了第二种方法。
Mean teacher 也是坚信“平均得就是最好的”(不知道是不是平均可以去噪的原因…orz),但是时序上的平均已经被 temporal ensembling 做了,因此 Mean teacher 提出了一个大胆的想法,我们对模型的参数进行移动平均(weight-averaged),使用这个移动平均模型参数的就是 teacher model 了,然后用 teacher model 来构造高质量 target。
一思索就觉得这想法好,对模型的参数进行平均,每次更新的网络的时候就能更新 teacher model,就能得到 target,不用像 temporal ensembling 那样等一个迭代期这么久,这对 online model 是致命的。