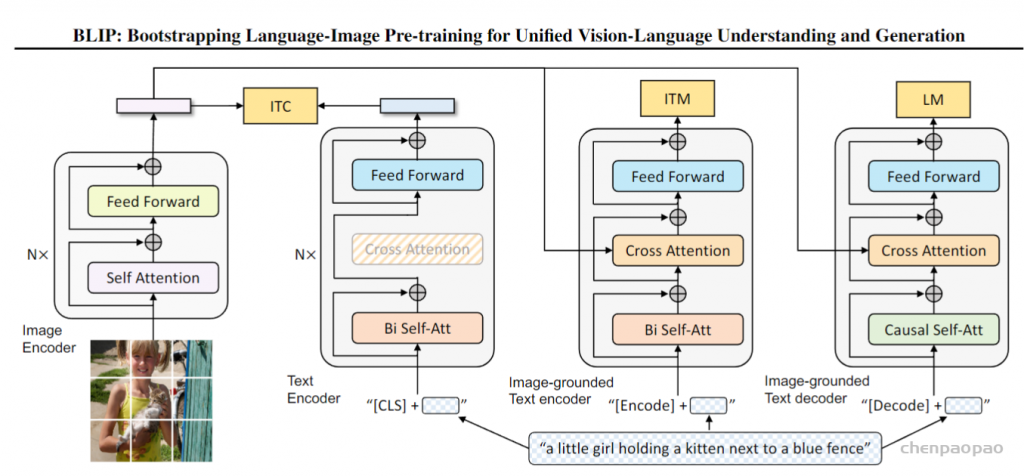
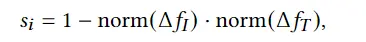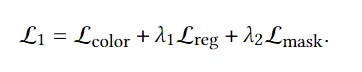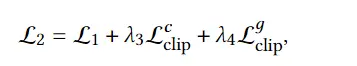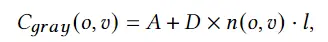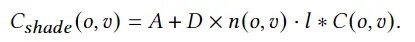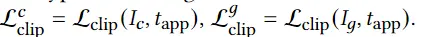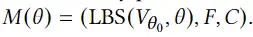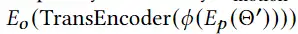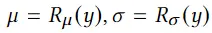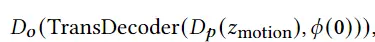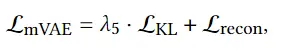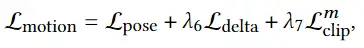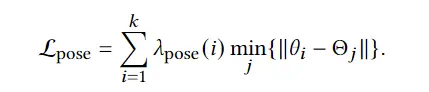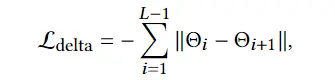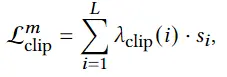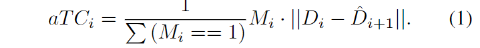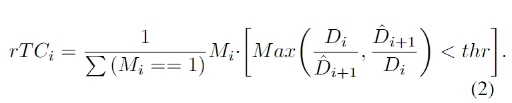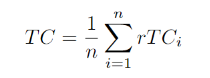1、编码器-解码器的多模态混合(MED, Multimodal mixture of Encoder-Decoder),一个全新的模型架构,能够有效地进行多任务预训练和灵活的迁移学习。一个MED可以作为一个单模态编码器(unimodal encoder),或是基于图像的文本编码器(image-grounded text encoder),或是基于图像的文本解码器(image-grounded text decoder)。
该模型与三个视觉语言目标共同进行预训练,即图像-文本对比学习(image-text contrastive learning)、图像-文本匹配(image-text matching)和图像-条件语言建模(image-conditioned language modeling)。
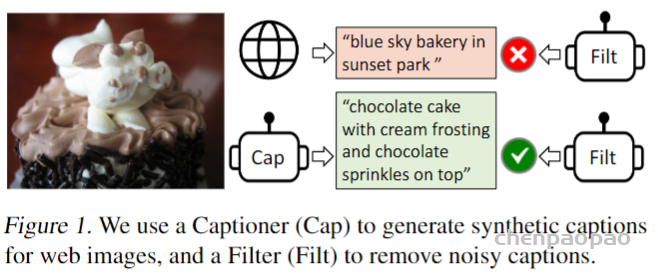
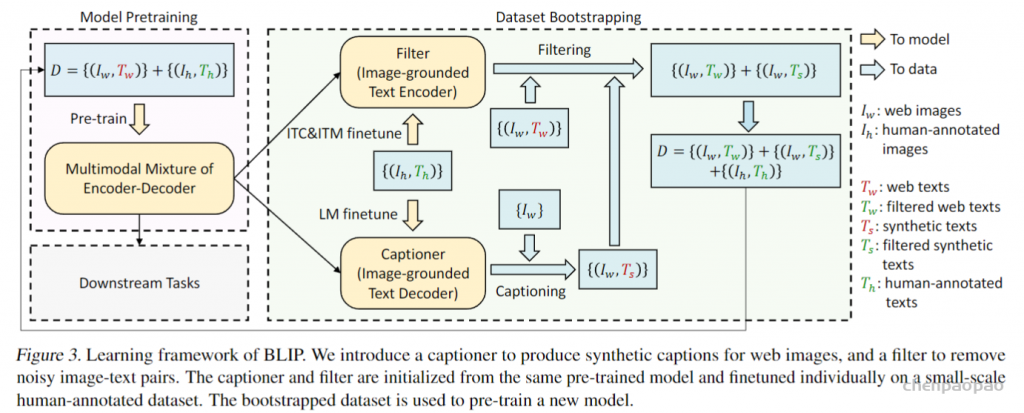
2、标题和过滤(Captioning and Filtering,CapFilt),一种新的数据集boostrapping方法,可以用于从噪声图像-文本对中学习。将预训练的MED微调为两个模块:一个是给定网络图像产生合成标题的captioner,另一个是去除原始网络文本和合成文本中的噪声标题的Filter。
2、以图像为基础的文本编码器(Image-grounded text encoder),通过在自注意力(SA)层和前馈网络(FFN)之间为文本编码器的每个Transformer块插入一个额外的交叉注意力(CA)层来注入视觉信息。一个特定任务的[Encode]标记被附加到文本上,[Encode]的输出embedding被用作图像-文本对的多模态表示。
3、以图像为基础的文本解码器(Image-grounded text decoder),用因果自注意力层(causal self-attention layer)替代编码器中的双向自注意力层。用[Decode]标记来表示一个序列的开始和结束。
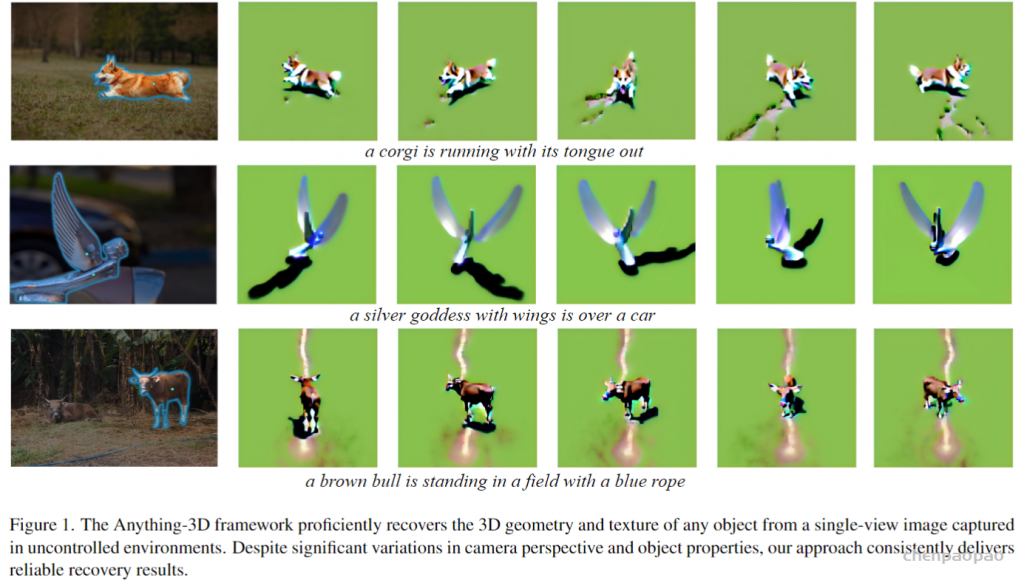
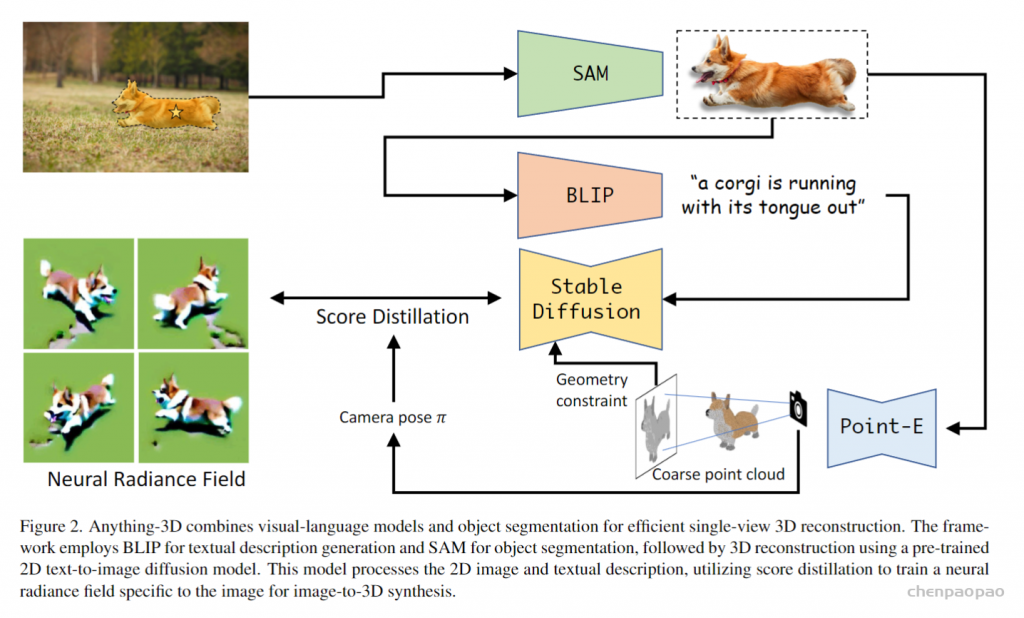
Here we present a project where we combine Segment Anything with a series of 3D models to create a very interesting demo. This is currently a small project, but we plan to continue improving it and creating more exciting demos.
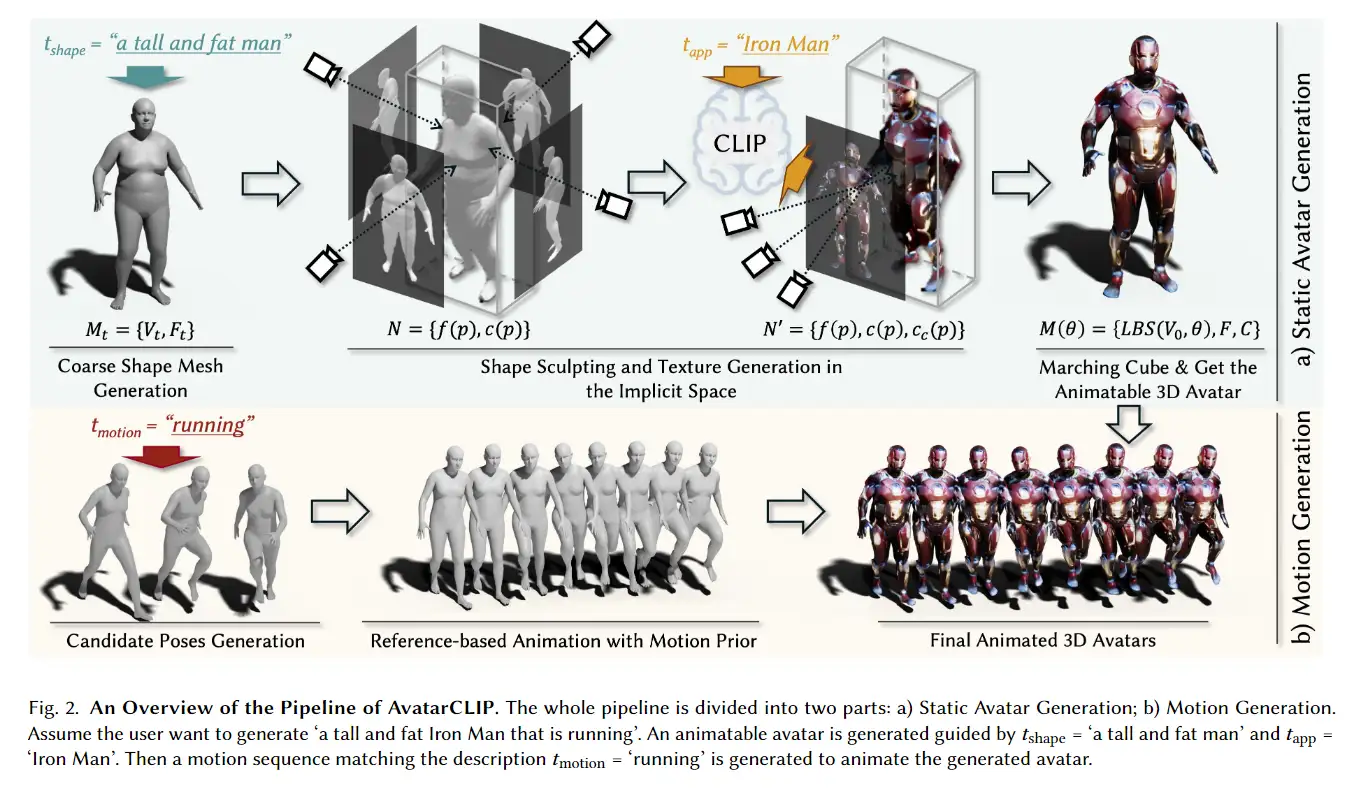
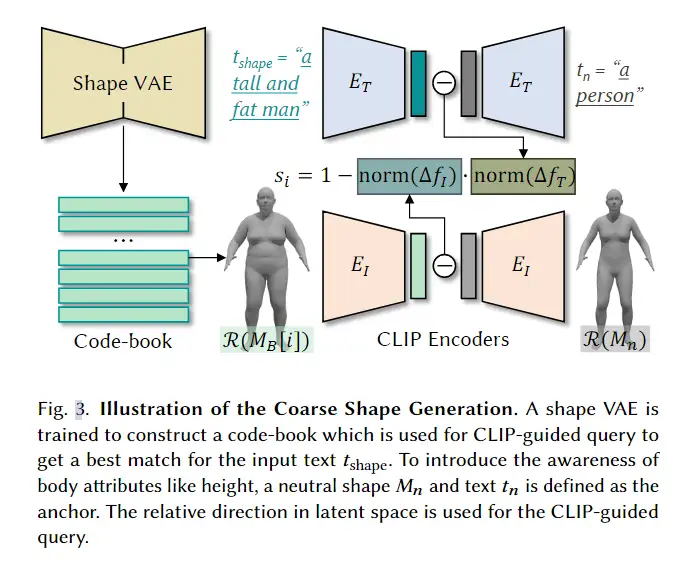
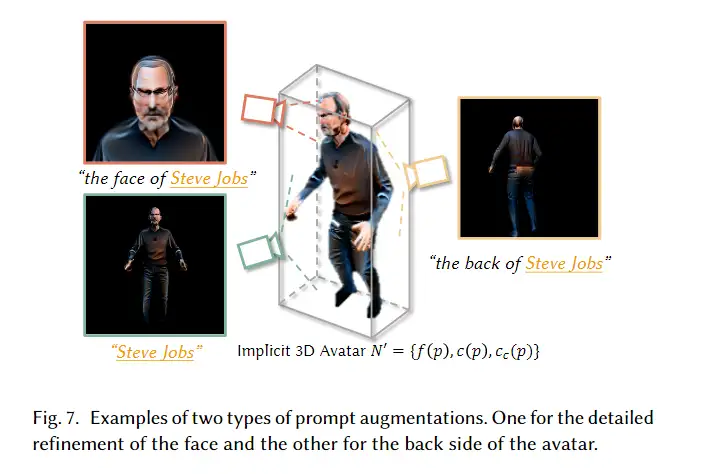
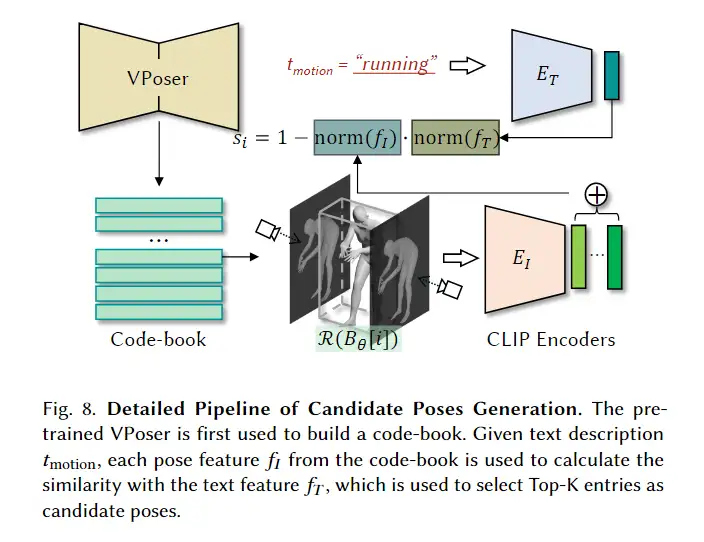
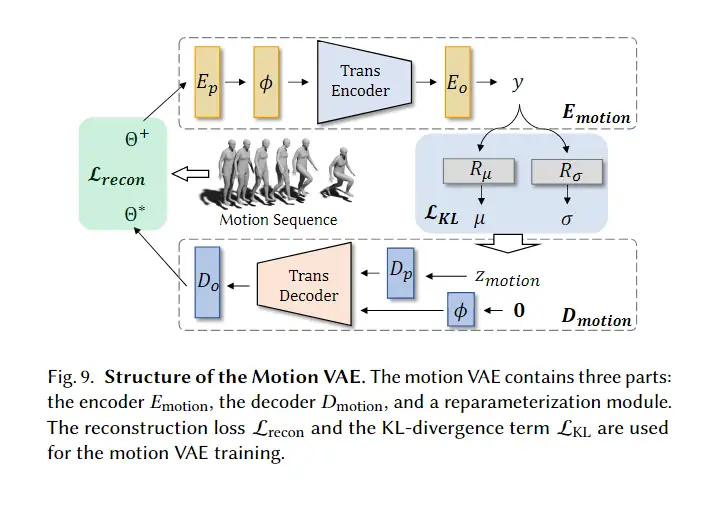
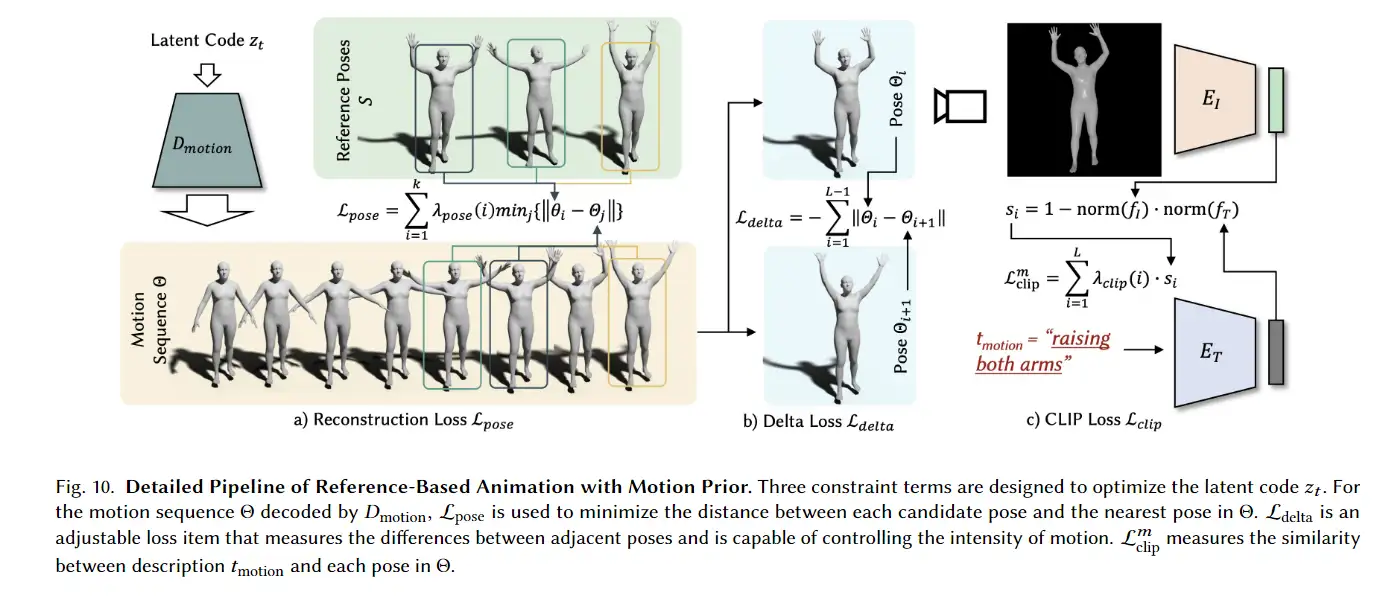
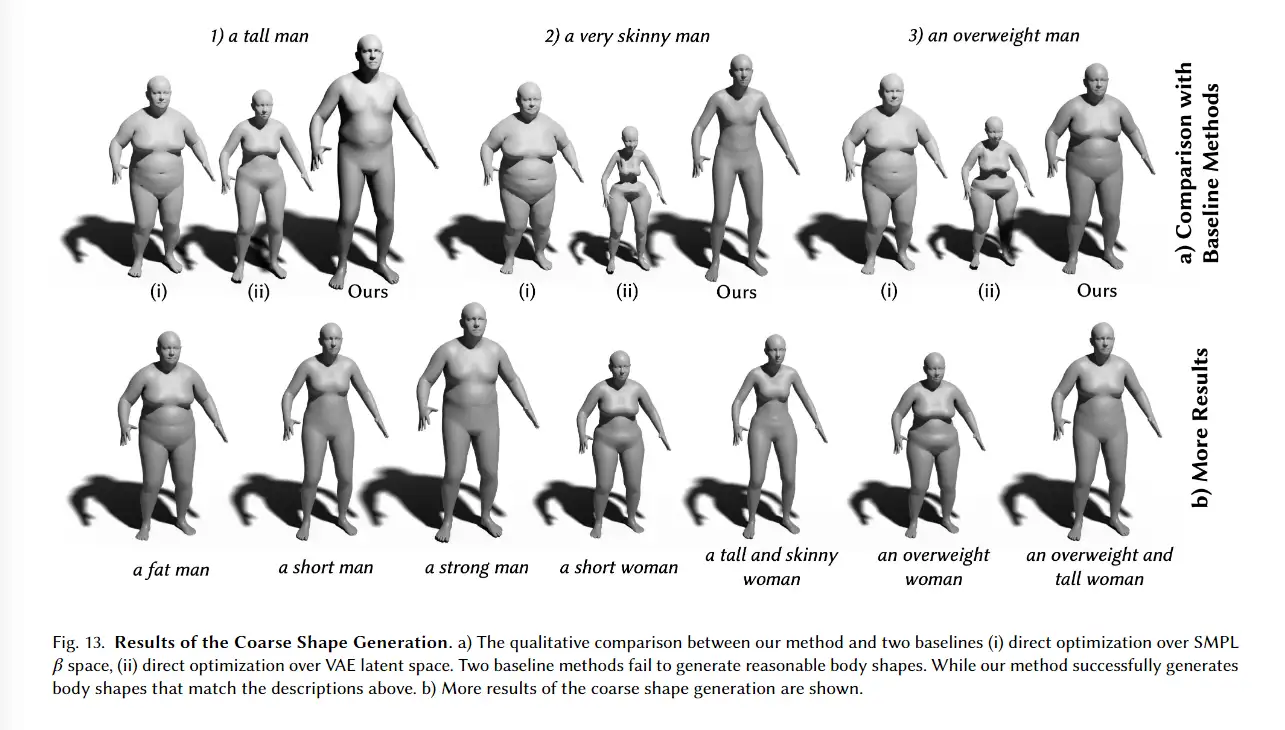
3D avatar生成在数字时代有至关重要的作用,一般而言,创建一个3Davatar需要创建一个人物形象、绘制纹理、建立骨架并使用捕捉到的动作对其进行驱动。无论哪一个步骤都需要专业人才、大量时间和昂贵的设备,为了让这项技术面向大众,本文提出了AvatarCLIP,一个zero-shot文本驱动的3Davatar生成和动画化的框架。与专业的制作软件不同,这个模型不需要专业知识,仅仅通过自然语言就可以生成想要的avatar。本文主要是利用了大规模的视觉语言预训练模型CLIP来监督人体的生成,包括几何形状、纹理和动画。使用shapeVAE来初始化人类几何形状,进一步进行体渲染,接着进行几何雕刻和纹理生成,利用motionVAE得到运动先验来生成三维动画
为了生成高质量的 3D avatar,形状和纹理需要进一步塑造和生成以匹配外观 app 的描述。如前所述,我们选择使用隐式表示,即 Neus,作为此步骤中的基本 3D 表示,因为它在几何和颜色上都具有优势。为了加速优化和控制形状生成,更方便生成动画,所以需要先将生成的粗糙mesh shape转化为隐式表示。
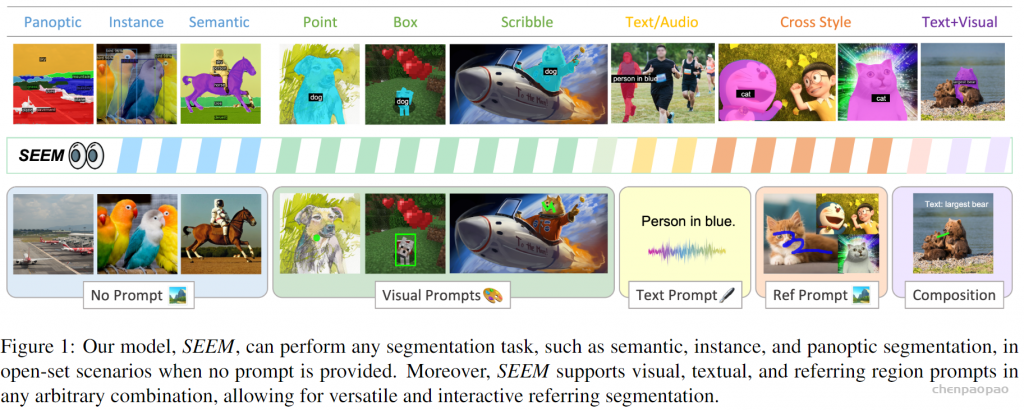
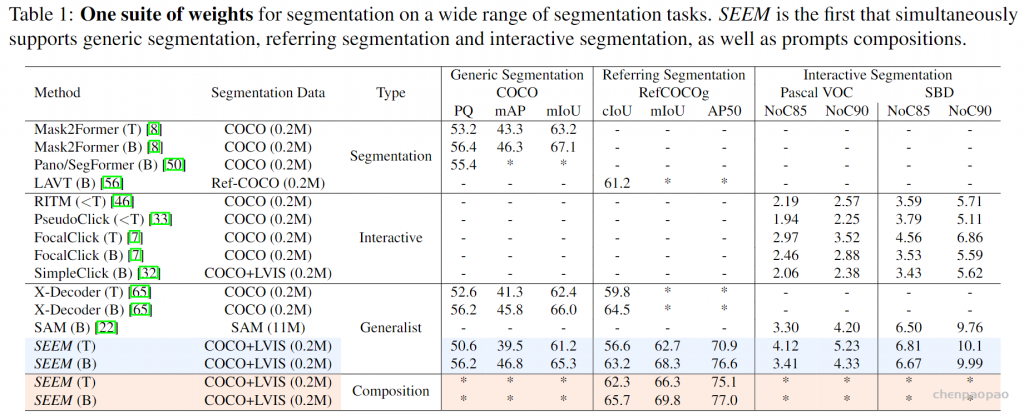
最近,一篇「一次性分割一切」的新论文《Segment Everything Everywhere All at Once》再次引起关注。在该论文中,来自威斯康星大学麦迪逊分校、微软、香港科技大学的几位华人研究者提出了一种基于 prompt 的新型交互模型 SEEM。SEEM 能够根据用户给出的各种模态的输入(包括文本、图像、涂鸦等等),一次性分割图像或视频中的所有内容,并识别出物体类别。该项目已经开源,并提供了试玩地址供大家体验。
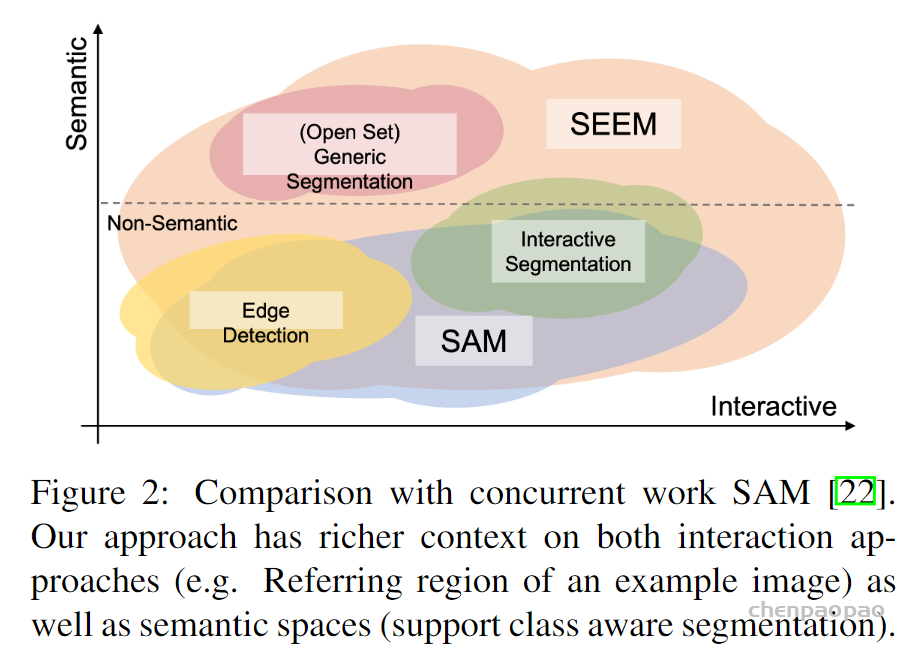
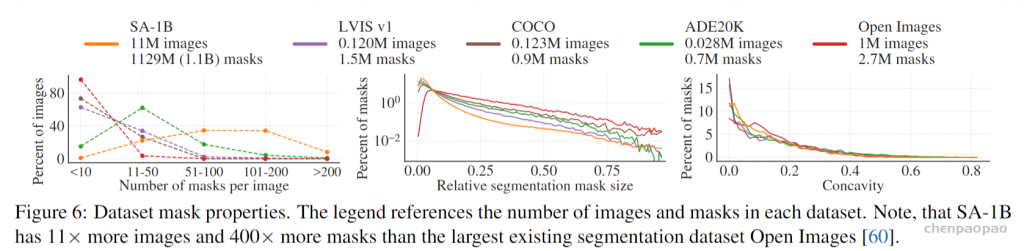
当然,SEEM 并不是完美的,其存在的两个主要限制为:训练数据规模有限,SEEM不支持基于部分的分割。我们通过利用更多的训练数据和监督,可以进一步提高模型性能,而基于部分的分割可以在不改变模型的情况下无缝地从中学习。最后,非常感谢 SAM 提出的分割数据集,这是是非常宝贵的资源,我们应该好好利用起来。
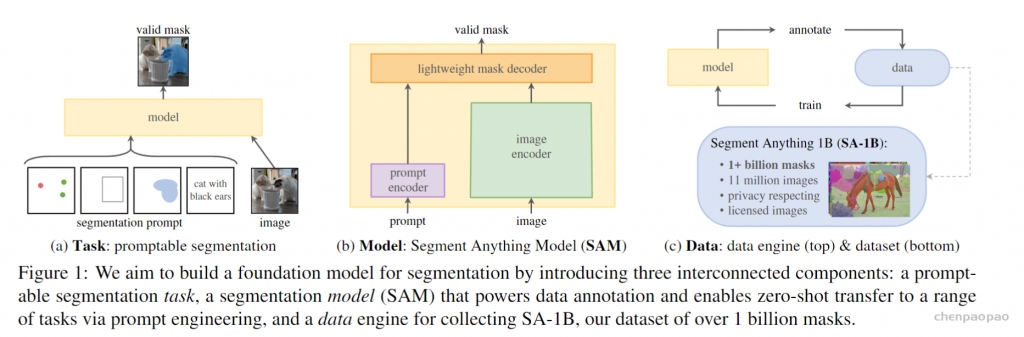
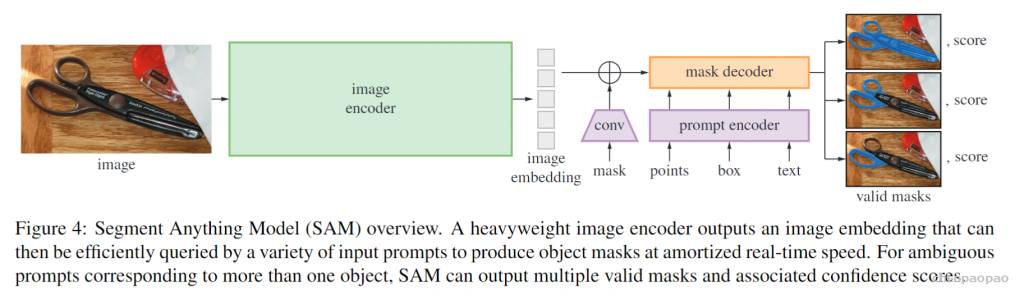
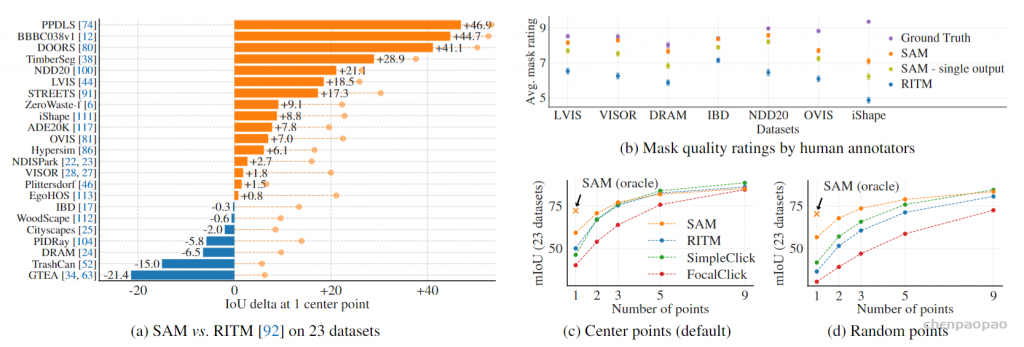
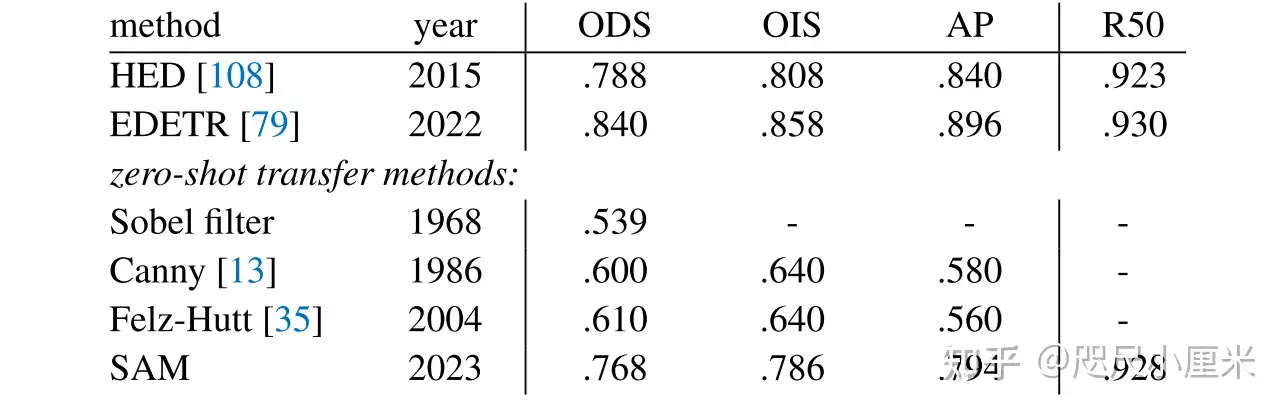
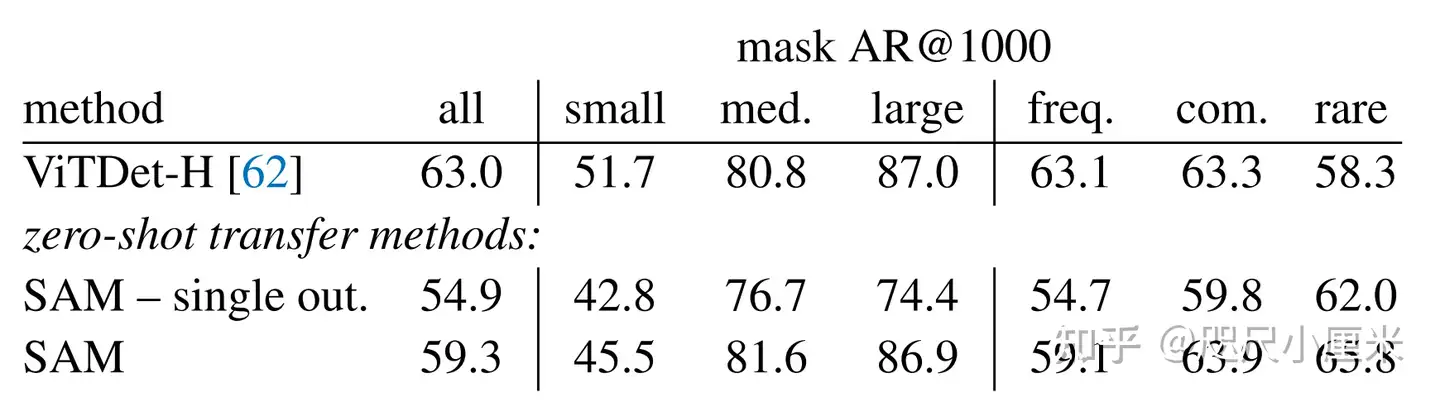
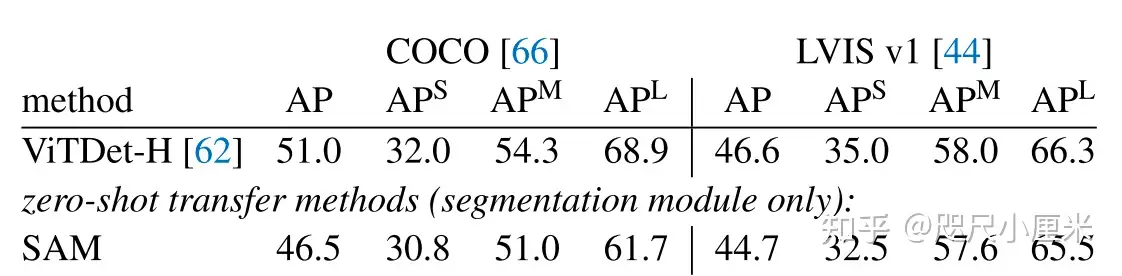
可提示的分割任务和现实世界使用的目标对模型架构施加了约束。具体地说,该模型必须支持灵活的提示,需要分摊实时计算掩码以允许交互式使用,并且必须具有歧义识别能力。作者发现一个简单的设计满足所有三个约束:一个强大的图像编码器计算一个图像嵌入,一个提示编码器嵌入提示,然后这两个信息源被组合在一个轻量级掩码解码器中,预测分割掩码。作者将此模型称为 Segment Anything 模型或 SAM。通过将 SAM 分离成一个图像编码器和一个快速提示编码器/掩码解码器,相同的图像嵌入可以在不同的提示下重复使用(及其成本分摊)。给定一个图像嵌入、提示编码器和掩码解码器在 ~50 毫秒的网络浏览器中根据提示预测掩码。 本文专注于点、框和掩码提示,并且还使用自由格式的文本提示呈现初始结果。为了使 SAM 具有歧义意识, 作者将其设计为预测单个提示的多个掩码,从而使 SAM 能够自然地处理歧义。
图像编码器:在可扩展性和强大的预训练方法的推动下,作者使用 MAE 预训练视觉ViT,最低限度地适应处理高分辨率输入。图像编码器每张图像运行一次,可以在提示模型之前应用。
限制:虽然 SAM 总体上表现良好,但并不完美。它可能会错过精细的结构,有时会产生不连贯的小组件的幻觉,并且不会像“放大”的计算密集型方法那样清晰地产生边界。一般来说,专用的交互式分割方法在提供许多点时优于 SAM。与这些方法不同,SAM 是为通用性和使用广度而不是高 IoU 交互式分割而设计的。 此外,SAM 可以实时处理提示,但是当使用重型图像编码器时,SAM 的整体性能并不是实时的。 本文中对 text-to-mask 任务的尝试是探索性的,并不完全可靠,尽管可以相信它可以通过更多的努力得到改进。 虽然 SAM 可以执行许多任务,但尚不清楚如何设计实现语义和全景分割的简单提示。
未来:预训练模型可以提供新功能,甚至超出训练时的想象(涌现现象)。一个突出的例子是 CLIP如何用作更大系统中的一个组件,例如 DALL·E。本文的目标是使用 SAM 使这种组合变得简单明了,通过要求 SAM 为广泛的分割提示预测有效掩码来实现这一目标。 效果是在 SAM 和其他组件之间创建可靠的接口。 例如,MCC可以轻松地使用 SAM 来分割感兴趣的对象,并实现对未见对象的强泛化,以便从单个 RGB-D 图像进行 3D 重建。在另一个示例中,SAM 可以通过可穿戴设备检测到的注视点进行提示,从而启用新的应用程序。 由于 SAM 能够泛化到第一视角的图像等新领域,这样的系统无需额外培训即可工作。
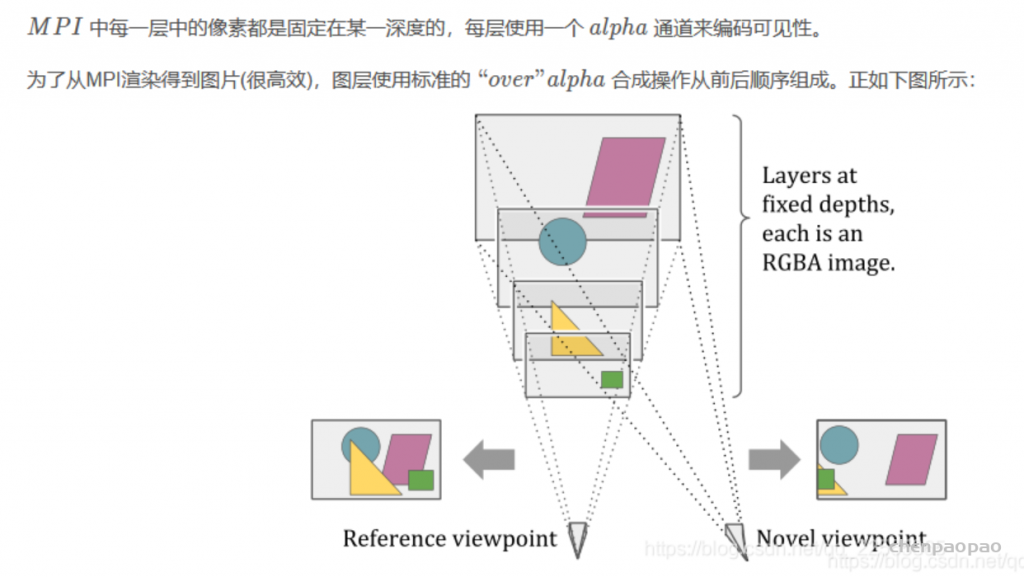
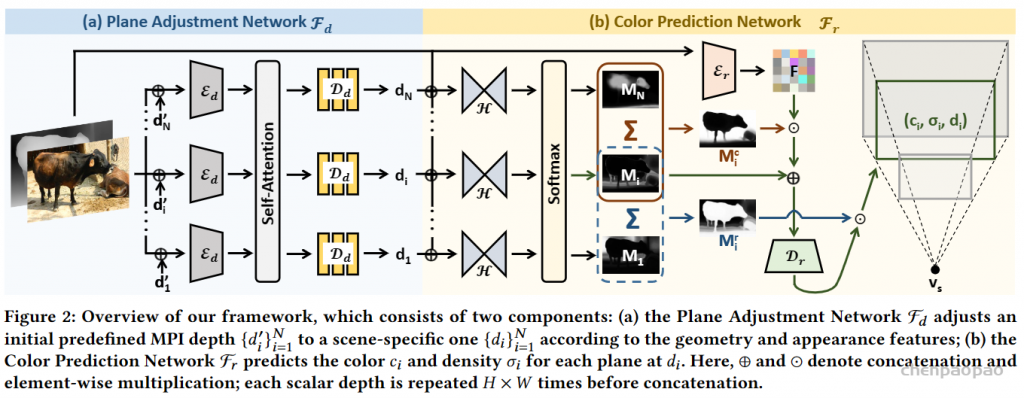
该网络旨在从输入图像和其深度图中预测N个平面,每个平面都有颜色通道ci、密度通道σi和深度di。该网络由两个子网络组成:平面调整网络Fd和颜色预测网络Fr。首先,使用现成的单目深度估计网络[Ranftl et al. 2021]获取深度图。然后,将Fd应用于推断平面深度{di}N_i=1,并将Fr应用于预测每个di处的颜色和密度{ci, σi}N_i=1。因此,该网络可以生成多平面图像,其中每个平面都具有不同的颜色、密度和深度值。