与WordPiece一样,Unigram Language Model(ULM)同样使用语言模型来挑选子词。不同之处在于,BPE和WordPiece算法的词表大小都是从小到大变化,属于增量法。而Unigram Language Model则是减量法,即先初始化一个大词表,根据评估准则不断丢弃词表,直到满足限定条件。ULM算法考虑了句子的不同分词可能,因而能够输出带概率的多个子词分段。
通常在每个单词末尾添加后缀</w>,统计每个单词出现的频率,例如,low的频率为5,那么我们将其改写为"l o w </ w>”:5 注:停止符</w>的意义在于标明subword是词后缀。举例来说:st不加</w>可以出现在词首,如st ar;加了</w>表明该子词位于词尾,如we st</w>,二者意义截然不同
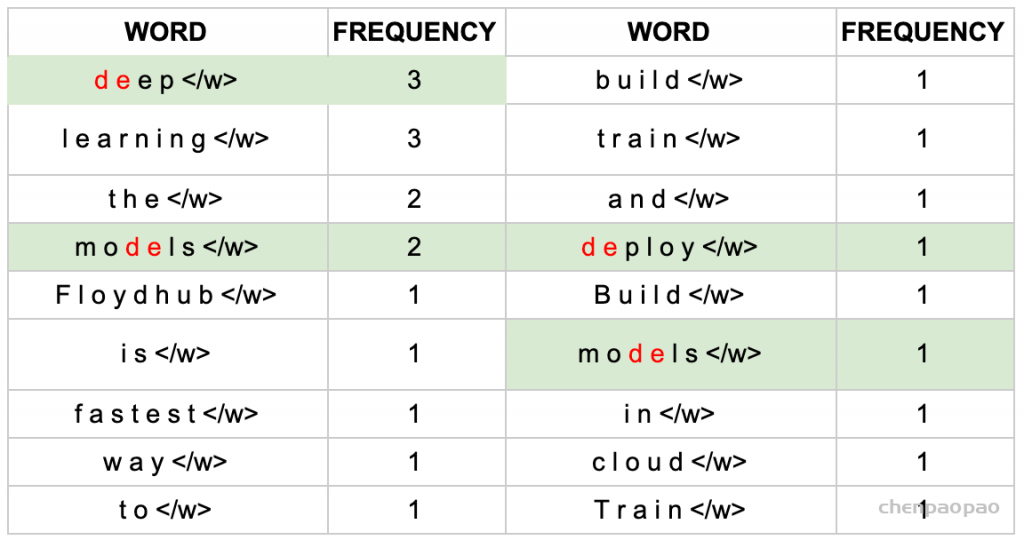
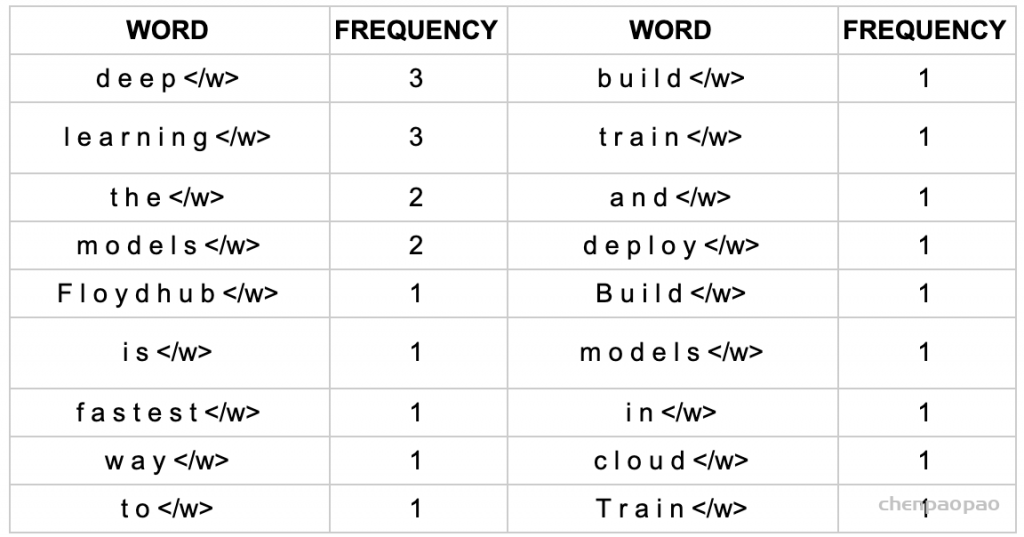
1、获取语料库,这样一段话为例:“FloydHub is the fastest way to build, train and deploy deep learning models. Build deep learning models in the cloud. Train deep learning models.”
2、拆分,加后缀,统计词频:
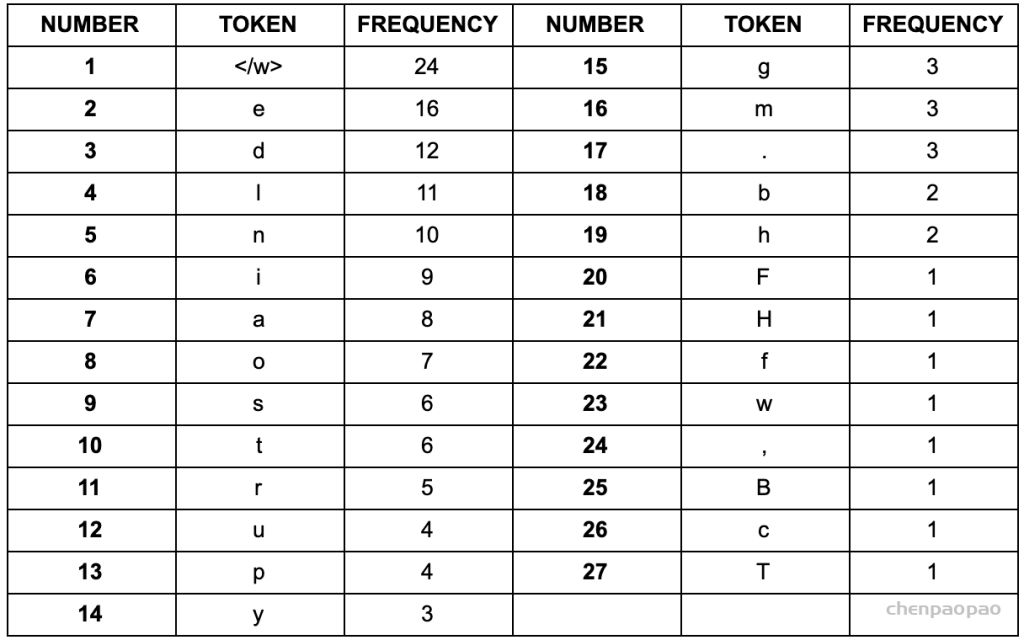
3、建立词表,统计字符频率(顺便排个序):
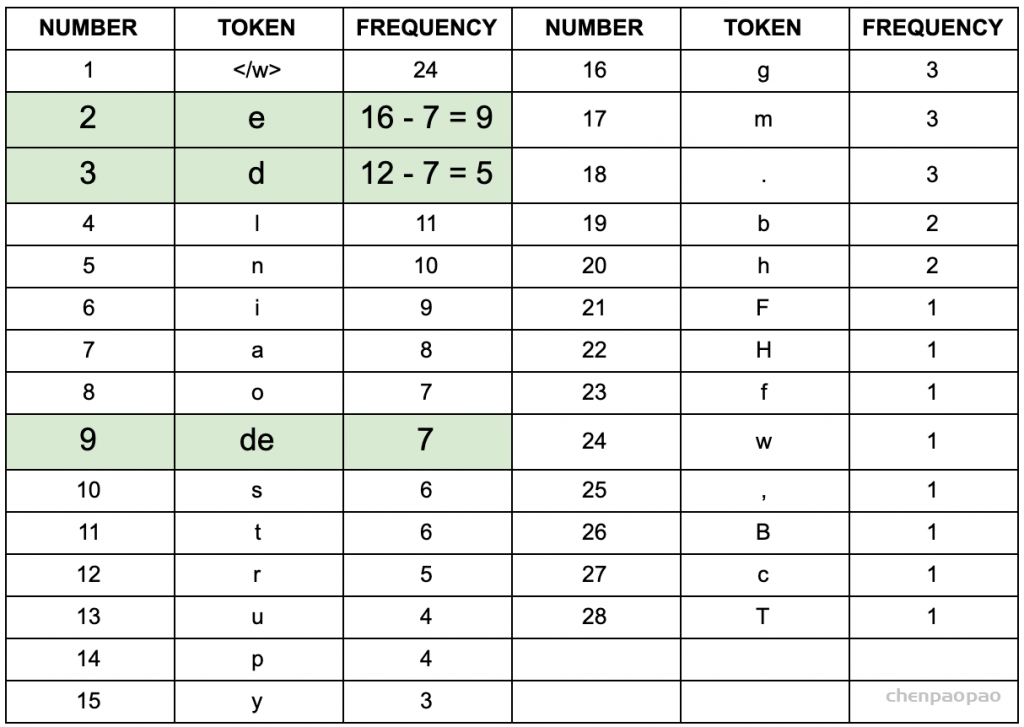
4、以第一次迭代为例,将字符频率最高的d和e替换为de,后面依次迭代:
5、更新词表 继续迭代直到达到预设的subwords词表大小或下一个最高频的字节对出现频率为1。
如果将词表大小设置为10,最终的结果为:
d e
r n
rn i
rni n
rnin g</w>
o de
ode l
m odel
l o
l e
import re, collections
def get_vocab(filename):
vocab = collections.defaultdict(int)
with open(filename, 'r', encoding='utf-8') as fhand:
for line in fhand:
words = line.strip().split()
for word in words:
vocab[' '.join(list(word)) + ' </w>'] += 1
return vocab
def get_stats(vocab):
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i],symbols[i+1]] += freq
return pairs
def merge_vocab(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
def get_tokens(vocab):
tokens = collections.defaultdict(int)
for word, freq in vocab.items():
word_tokens = word.split()
for token in word_tokens:
tokens[token] += freq
return tokens
跑一个例子试一下,这里已经对原句子进行了预处理:
vocab = {'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3}
print('==========')
print('Tokens Before BPE')
tokens = get_tokens(vocab)
print('Tokens: {}'.format(tokens))
print('Number of tokens: {}'.format(len(tokens)))
print('==========')
num_merges = 5
for i in range(num_merges):
pairs = get_stats(vocab)
if not pairs:
break
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
print('Iter: {}'.format(i))
print('Best pair: {}'.format(best))
tokens = get_tokens(vocab)
print('Tokens: {}'.format(tokens))
print('Number of tokens: {}'.format(len(token

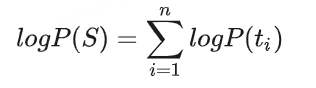
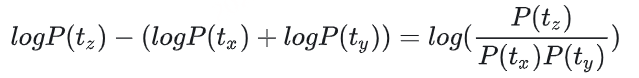
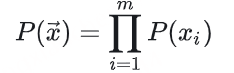
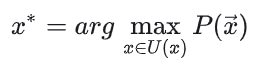
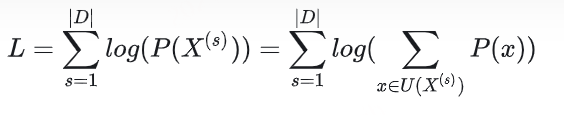
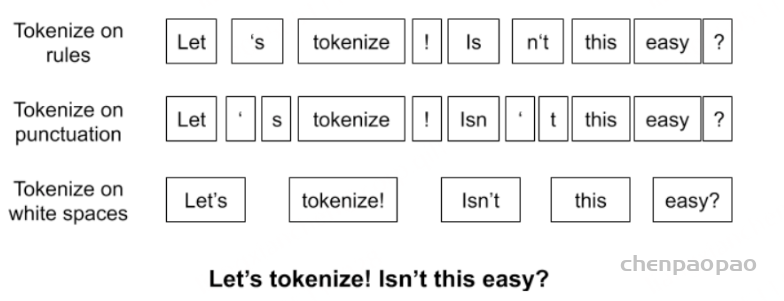



 继续迭代直到达到预设的subwords词表大小或下一个最高频的字节对出现频率为1。
继续迭代直到达到预设的subwords词表大小或下一个最高频的字节对出现频率为1。