
- HuggingFace 地址:https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f
- 技术报告:https://github.com/QwenLM/Qwen3/blob/main/Qwen3_Technical_Report.pdf
- Modelscope 地址:https://modelscope.cn/collections/Qwen3-9743180bdc6b48
- GitHub 地址:https://github.com/QwenLM/Qwen3
- 博客地址:https://qwenlm.github.io/blog/qwen3/
- 试用地址:https://chat.qwen.ai/
- MoE 模型:Qwen3-235B-A22B 和 Qwen3-30B-A3B;其中 235B 和 30B 分别是总参数量,22B 和 3B 分别是激活参数量。
- 密集模型:Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B 和 Qwen3-0.6B。

整体架构:
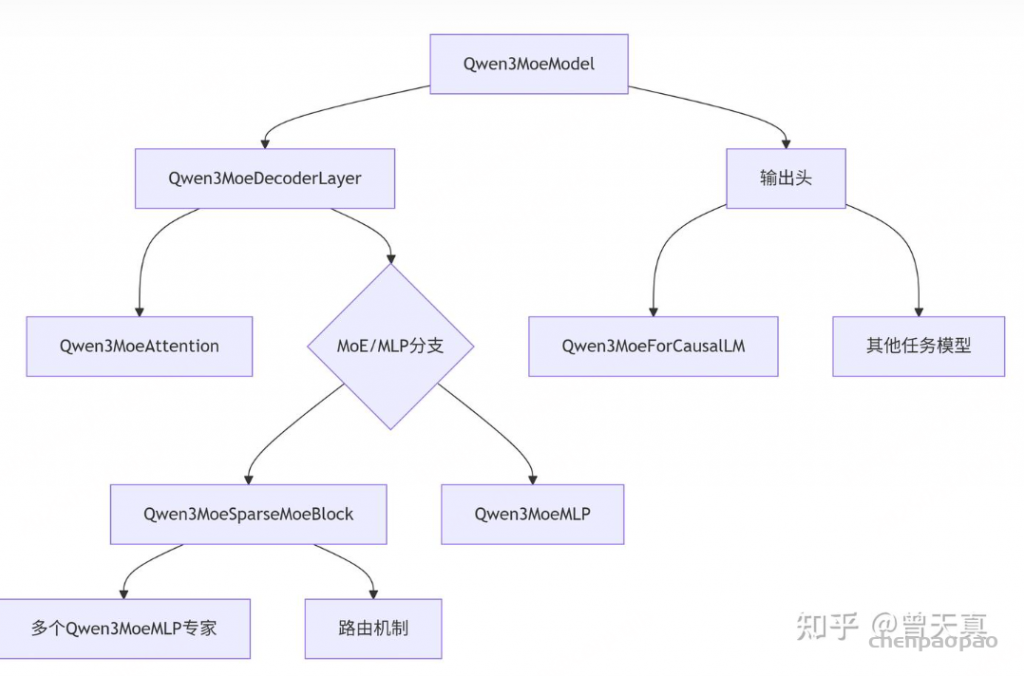
1) 包含num_experts个轻量级专家网络(Qwen3MoeMLP)的并行计算单元;
2) 基于注意力机制的路由网络(gate)。
在计算过程中,路由网络通过动态决策机制为每个输入Token生成路由决策,筛选出匹配度最高的top_k个专家节点。随后,系统将根据路由权重对选定专家的计算结果进行加权融合,最终生成该隐层的表征输出。
那么同样我们对比DeepSeekMOE,Qwen3MOE有两个点的改变:
1)没有shared expert。
2) 优化了MLP架构,变为Qwen3MoeSparseMoeBlock。

模型特性优化总结表:
| 特性 | 实现细节 |
| 注意力机制 | 改进的Qwen3Attention(支持Flash Attention优化) |
| MoE路由策略 | Top-K专家选择(默认K=2),支持权重归一化 |
| 专家结构 | 每个专家为标准MLP(hidden_size → moe_intermediate_size → hidden_size) |
| 动态专家分配 | 每间隔decoder_sparse_step层使用MoE(其他层使用标准MLP) |
| 负载均衡机制 | 通过router_logits计算辅助损失,防止专家极化 |
| 计算优化 | 使用index_add操作实现零浪费的专家计算 |
对比传统MOE优化效果:
| 优化方向 | Qwen3-MoE实现方案 | 对比传统MoE模型优势 |
| 路由机制 | Top-K + 动态权重归一化(norm_topk_prob) | 缓解专家利用不均衡问题,相比Mixtral的固定权重分配更灵活 |
| 稀疏模式 | 分层动态稀疏(decoder_sparse_step控制MoE层间隔) | 混合密集与稀疏计算,相比全MoE结构降低计算开销 |
| 内存优化 | logits_to_keep参数支持部分logits计算 | 长序列生成时内存占用减少,优于Mixtral的全序列计算 |
| 注意力机制 | 改进的Flash Attention 3.0集成 | 相比标准Attention实现,训练速度提升,显存占用减少 |
| 负载均衡 | 改进的辅助损失函数(load_balancing_loss_func+自研调整系数) | 专家利用率从Mixtral的提升,防止专家极化 |
| 动态计算 | mlp_only_layers参数跳过MoE层 | 支持按需切换密集/稀疏模式,相比固定结构推理灵活性提升 |
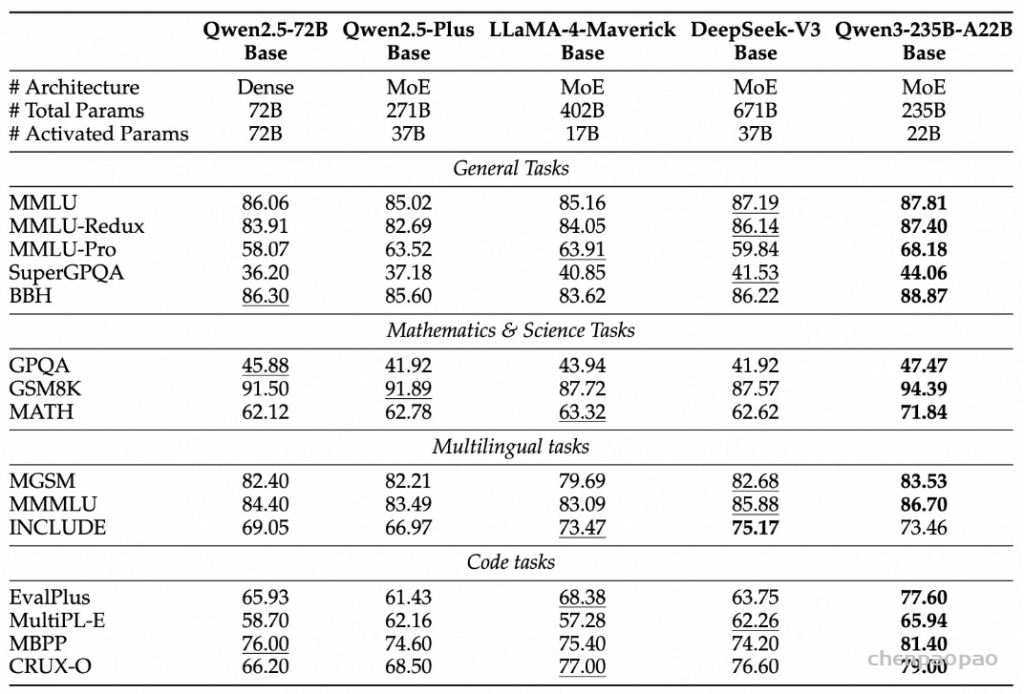
性能方面,在代码、数学、通用能力等基准测试中,旗舰模型 Qwen3-235B-A22B 与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型表现相当。

此外,小型 MoE 模型 Qwen3-30B-A3B 的激活参数数量是 QwQ-32B 的 10%,表现却更胜一筹。甚至像 Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能。

性能大幅提升的同时,Qwen3 的部署成本还大幅下降,仅需 4 张 H20 即可部署满血版,显存占用仅为性能相近模型的三分之一。
核心亮点
- 多种思考模式
Qwen3 模型支持两种思考模式:
- 思考模式:在这种模式下,模型会逐步推理,经过深思熟虑后给出最终答案。这种方法非常适合需要深入思考的复杂问题。
- 非思考模式:在此模式中,模型提供快速、近乎即时的响应,适用于那些对速度要求高于深度的简单问题。
这种灵活性使用户能够根据具体任务控制模型进行“思考”的程度。例如,复杂的问题可以通过扩展推理步骤来解决,而简单的问题则可以直接快速作答,无需延迟。至关重要的是,这两种模式的结合大大增强了模型实现稳定且高效的“思考预算”控制能力。如上文所述,Qwen3 展现出可扩展且平滑的性能提升,这与分配的计算推理预算直接相关。这样的设计让用户能够更轻松地为不同任务配置特定的预算,在成本效益和推理质量之间实现更优的平衡。
下图为在 AIME24、AIME25、LiveCodeBech(v5)和 GPQA Diamond 等基准测试集中,非思考模式与思考模式的思考预算变化趋势。

- 多语言
Qwen3 模型支持 119 种语言和方言。这一广泛的多语言能力为国际应用开辟了新的可能性,让全球用户都能受益于这些模型的强大功能。
| 语系 | 语种&方言 |
|---|---|
| 印欧语系 | 英语、法语、葡萄牙语、德语、罗马尼亚语、瑞典语、丹麦语、保加利亚语、俄语、捷克语、希腊语、乌克兰语、西班牙语、荷兰语、斯洛伐克语、克罗地亚语、波兰语、立陶宛语、挪威语(博克马尔语)、挪威尼诺斯克语、波斯语、斯洛文尼亚语、古吉拉特语、拉脱维亚语、意大利语、奥克语、尼泊尔语、马拉地语、白俄罗斯语、塞尔维亚语、卢森堡语、威尼斯语、阿萨姆语、威尔士语、西里西亚语、阿斯图里亚语、恰蒂斯加尔语、阿瓦德语、迈蒂利语、博杰普尔语、信德语、爱尔兰语、法罗语、印地语、旁遮普语、孟加拉语、奥里雅语、塔吉克语、东意第绪语、伦巴第语、利古里亚语、西西里语、弗留利语、撒丁岛语、加利西亚语、加泰罗尼亚语、冰岛语、托斯克语、阿尔巴尼亚语、林堡语、罗马尼亚语、达里语、南非荷兰语、马其顿语僧伽罗语、乌尔都语、马加希语、波斯尼亚语、亚美尼亚语 |
| 汉藏语系 | 中文(简体中文、繁体中文、粤语)、缅甸语 |
| 亚非语系 | 阿拉伯语(标准语、内志语、黎凡特语、埃及语、摩洛哥语、美索不达米亚语、塔伊兹-阿德尼语、突尼斯语)、希伯来语、马耳他语 |
| 南岛语系 | 印度尼西亚语、马来语、他加禄语、宿务语、爪哇语、巽他语、米南加保语、巴厘岛语、班加语、邦阿西楠语、伊洛科语、瓦雷语(菲律宾) |
| 德拉威语 | 泰米尔语、泰卢固语、卡纳达语、马拉雅拉姆语 |
| 突厥语系 | 土耳其语、北阿塞拜疆语、北乌兹别克语、哈萨克语、巴什基尔语、鞑靼语 |
| 壮侗语系 | 泰语、老挝语 |
| 乌拉尔语系 | 芬兰语、爱沙尼亚语、匈牙利语 |
| 南亚语系 | 越南语、高棉语 |
| 其他 | 日语、韩语、格鲁吉亚语、巴斯克语、海地语、帕皮阿门托语、卡布维尔迪亚努语、托克皮辛语、斯瓦希里语 |
- 增强的 Agent 能力
我们优化了 Qwen3 模型的 Agent 和 代码能力,同时也加强了对 MCP 的支持。
预训练
在预训练方面,Qwen3 的数据集相比 Qwen2.5 有了显著扩展。Qwen2.5是在 18 万亿个 token 上进行预训练的,而 Qwen3 使用的数据量几乎是其两倍,达到了约 36 万亿个 token,涵盖了 119 种语言和方言。为了构建这个庞大的数据集,我们不仅从网络上收集数据,还从 PDF 文档中提取信息。我们使用 Qwen2.5-VL 从这些文档中提取文本,并用 Qwen2.5 改进提取内容的质量。为了增加数学和代码数据的数量,我们利用 Qwen2.5-Math 和 Qwen2.5-Coder 这两个数学和代码领域的专家模型合成数据,合成了包括教科书、问答对以及代码片段等多种形式的数据。
Qwen3模型采用三阶段预训练过程:
- 通用阶段 (S1): 在第一阶段,所有Qwen3模型使用4,096 token的序列长度,在超过30万亿token的数据上进行训练 。此阶段旨在建立模型的语言能力和通用世界知识基础,训练数据覆盖119种语言和方言 。
- 推理阶段 (S2): 为了进一步提升推理能力,此阶段的预训练语料库增加了STEM、编码、推理和合成数据的比例 。模型使用4,096 token的序列长度,在约5万亿高质量token上进行进一步预训练 。在此阶段还加速了学习率衰减 。
- 长上下文阶段: 在最后一个预训练阶段,收集高质量长上下文语料库,将Qwen3模型的上下文长度扩展到32,768 token 。长上下文语料库中,75%的文本长度在16,384到32,768 token之间,25%的文本长度在4,096到16,384 token之间 。报告提及沿用Qwen2.5的做法,使用ABF技术将RoPE的基础频率从10,000提高到1,000,000 。同时,引入YARN和Dual Chunk Attention (DCA)技术,在推理过程中实现序列长度容量的四倍增长 。
类似于Qwen2.5,Qwen3根据这三个预训练阶段开发了最优超参数(如学习率调度器和批次大小)预测的缩放律 。通过广泛实验,系统研究了模型架构、训练数据、训练阶段与最优训练超参数之间的关系 。最终为每个密集模型和MoE模型设定了预测的最优学习率和批次大小策略。
由于模型架构的改进、训练数据的增加以及更有效的训练方法,Qwen3 Dense 基础模型的整体性能与参数更多的Qwen2.5基础模型相当。例如,Qwen3-1.7B/4B/8B/14B/32B-Base 分别与 Qwen2.5-3B/7B/14B/32B/72B-Base 表现相当。特别是在 STEM、编码和推理等领域,Qwen3 Dense 基础模型的表现甚至超过了更大规模的 Qwen2.5 模型。对于 Qwen3 MoE 基础模型,它们在仅使用 10% 激活参数的情况下达到了与 Qwen2.5 Dense 基础模型相似的性能。这带来了训练和推理成本的显著节省。
后训练

为了开发能够同时具备思考推理和快速响应能力的混合模型,我们实施了一个四阶段的训练流程。该流程包括:(1)长思维链冷启动,(2)长思维链强化学习,(3)思维模式融合,以及(4)通用强化学习。
后训练部分详细介绍了Qwen3模型的后训练流程和评估结果 。Qwen3的后训练流程策略性地设计了两个核心目标:思维控制和强到弱蒸馏 。
思维控制 (Thinking Control):
思维控制涉及将“非思维”模式和“思维”模式集成到模型中,为用户提供灵活性,选择模型是否进行推理,并通过指定思维过程的token预算来控制思考的深度 。
强到弱蒸馏 (Strong-to-Weak Distillation):
强到弱蒸馏旨在优化轻量级模型的后训练过程 。通过利用大型模型的知识,显著降低了构建小型模型所需的计算成本和开发工作 。
如图1所示,Qwen3系列的旗舰模型遵循复杂的四阶段训练过程 。前两个阶段侧重于发展模型的“思维”能力 。后两个阶段旨在将强大的“非思维”功能整合到模型中 。
初步实验表明,将教师模型的输出logit直接蒸馏到轻量级学生模型中,可以有效增强其性能,同时保持对其推理过程的细粒度控制 。这种方法避免了为每个小型模型单独执行详尽的四阶段训练过程 。它带来了更好的即时性能(通过更高的Pass@1分数体现),也提高了模型的探索能力(通过改进的Pass@64结果反映) 。此外,它以更高的训练效率实现了这些提升,所需的GPU小时仅为四阶段训练方法的1/10 。
在第一阶段,我们使用多样的的长思维链数据对模型进行了微调,涵盖了数学、代码、逻辑推理和 STEM 问题等多种任务和领域。这一过程旨在为模型配备基本的推理能力。后训练始于策划一个涵盖数学、代码、逻辑推理和通用STEM问题等广泛类别的综合数据集 。数据集中的每个问题都配有经过验证的参考答案或基于代码的测试用例 。该数据集作为长链式思维(long-CoT)训练“冷启动”阶段的基础 。数据集构建涉及严格的两阶段过滤过程:查询过滤和响应过滤 。报告详细描述了过滤过程,包括使用Qwen2.5-72B-Instruct识别和移除不易验证的查询,排除无需CoT推理即可正确回答的查询,以及对生成的候选响应进行多项标准的严格过滤 。此阶段的目标是在模型中注入基础的推理模式,而不过度强调即时推理性能 。
第二阶段的重点是大规模强化学习,利用基于规则的奖励来增强模型的探索和钻研能力。推理RL阶段使用的查询-验证对必须满足四个标准:未在冷启动阶段使用、对冷启动模型可学习、尽可能具有挑战性、涵盖广泛的子领域 。共收集了3,995对查询-验证对,并使用GRPO更新模型参数 。报告提及使用大批次大小和每次查询多次rollout,以及利用离线训练提高样本效率,对训练过程有益 。通过控制模型的熵,平衡探索和利用,实现了训练和验证性能的持续改进 。例如,Qwen3-235B-A22B模型的AIME’24分数在170个RL训练步骤中从70.1提高到85.1
在第三阶段,我们在一份包括长思维链数据和常用的指令微调数据的组合数据上对模型进行微调,将非思考模式整合到思考模型中。确保了推理和快速响应能力的无缝结合。思维模式融合阶段的目标是将“非思维”能力整合到之前开发的“思维”模型中 。这允许开发者管理和控制推理行为,同时降低部署独立模型处理思维和非思维任务的成本和复杂性 。为此,在推理RL模型上进行持续监督微调(SFT),并设计聊天模板来融合两种模式 。

SFT数据构建:SFT数据集结合了“思维”和“非思维”数据 。为了不损害第二阶段模型的性能,“思维”数据是使用第二阶段模型本身通过对第一阶段查询进行拒绝采样生成的 。“非思维”数据则精心策划,涵盖编码、数学、指令遵循、多语言任务、创意写作、问答和角色扮演等广泛任务 。报告还提及使用自动生成的清单评估“非思维”数据的响应质量,并增加低资源语言翻译任务的比例以增强性能 。
聊天模板设计:为了更好地集成两种模式并允许用户动态切换模型的思维过程,Qwen3设计了聊天模板 。通过在用户查询或系统消息中引入/think和/no think标志,模型可以根据用户的输入选择适当的思维模式 。即使在非思维模式样本中,也保留了空的思维块,以确保模型内部格式的一致性 。默认情况下,模型在思维模式下运行,因此也包含一些用户查询不含/think标志的思维模式训练样本 。对于更复杂的多轮对话,随机插入多个/think和/no think标志,模型响应遵循最后遇到的标志 。
思维预算:思维模式融合的另一个优势是,一旦模型学会以非思维和思维模式响应,它自然会发展出处理中间情况的能力——基于不完整的思考生成响应 。这为实现模型思维过程的预算控制奠定了基础 。当模型的思考长度达到用户定义的阈值时,会手动停止思考过程并插入停止思考指令,然后模型根据其累积的推理生成最终响应 。报告指出,这种能力并非显式训练所得,而是思维模式融合应用自然产生的结果 。
最后,在第四阶段,我们在包括指令遵循、格式遵循和 Agent 能力等在内的 20 多个通用领域的任务上应用了强化学习,以进一步增强模型的通用能力并纠正不良行为。
通用RL阶段旨在广泛增强模型在各种场景下的能力和稳定性 。为此,建立了覆盖20多个不同任务的复杂奖励系统,每个任务都有定制的评分标准 。这些任务专门针对以下核心能力的提升:指令遵循、格式遵循、偏好对齐、Agent能力和专业场景下的能力(如RAG任务) 。
报告提及使用了三种不同类型的奖励来提供反馈:基于规则的奖励(用于推理RL阶段和通用任务,如指令遵循和格式遵循)、基于模型的奖励(带参考答案,允许更灵活地处理多样化任务)、基于模型的奖励(不带参考答案,利用人类偏好数据训练奖励模型,处理更广泛的查询并增强模型的互动性和帮助性)。
强到弱蒸馏 (Strong-to-Weak Distillation):
强到弱蒸馏流程专门为优化轻量级模型而设计,包括5个密集模型(Qwen3-0.6B、1.7B、4B、8B和14B)和1个MoE模型(Qwen3-30B-A3B)。这种方法在增强模型性能的同时,有效赋予了强大的模式切换能力 。蒸馏过程分为两个主要阶段:
- 离线蒸馏 (Off-policy Distillation): 在初始阶段,结合教师模型在
/think和/no think模式下生成的输出进行响应蒸馏 。这有助于轻量级学生模型发展基本的推理技能和在不同思维模式之间切换的能力 。 - 在线蒸馏 (On-policy Distillation): 在此阶段,学生模型生成在线序列进行微调 。具体来说,采样提示,学生模型以
/think或/no think模式生成响应 。然后通过将学生的logit与教师模型(Qwen3-32B或Qwen3-235B-A22B)的logit对齐,最小化KL散度来微调学生模型 。
通过评估Qwen3-32B模型在不同训练阶段的性能,报告得出结论:第三阶段将非思维模式整合到模型中,模型开始具备模式切换的初步能力 。第三阶段还增强了思维模式下的通用和指令遵循能力 。第四阶段进一步加强了模型在思维和非思维模式下的通用、指令遵循和Agent能力,确保了准确的模式切换 。
然而,对于知识、STEM、数学和编码等任务,思维模式融合和通用RL并未带来显著改进,甚至在一些挑战性任务上,思维模式下的性能有所下降 。报告推测这种性能下降是由于模型在更广泛的通用任务上进行训练,可能会损害其在处理复杂问题时的专业能力,并表示在Qwen3开发过程中接受了这种性能权衡以增强模型的整体多功能性 。
高级用法:
我们提供了一种软切换机制,允许用户在 enable_thinking=True 时动态控制模型的行为。具体来说,您可以在用户提示或系统消息中添加 /think 和 /no_think 来逐轮切换模型的思考模式。在多轮对话中,模型会遵循最近的指令。
未来发展:
Qwen3 代表了我们在通往通用人工智能(AGI)和超级人工智能(ASI)旅程中的一个重要里程碑。通过扩大预训练和强化学习的规模,我们实现了更高层次的智能。我们无缝集成了思考模式与非思考模式,为用户提供了灵活控制思考预算的能力。此外,我们还扩展了对多种语言的支持,帮助全球更多用户。
展望未来,我们计划从多个维度提升我们的模型。这包括优化模型架构和训练方法,以实现几个关键目标:扩展数据规模、增加模型大小、延长上下文长度、拓宽模态范围,并利用环境反馈推进强化学习以进行长周期推理。我们认为,我们正从专注于训练模型的时代过渡到以训练 Agent 为中心的时代。