
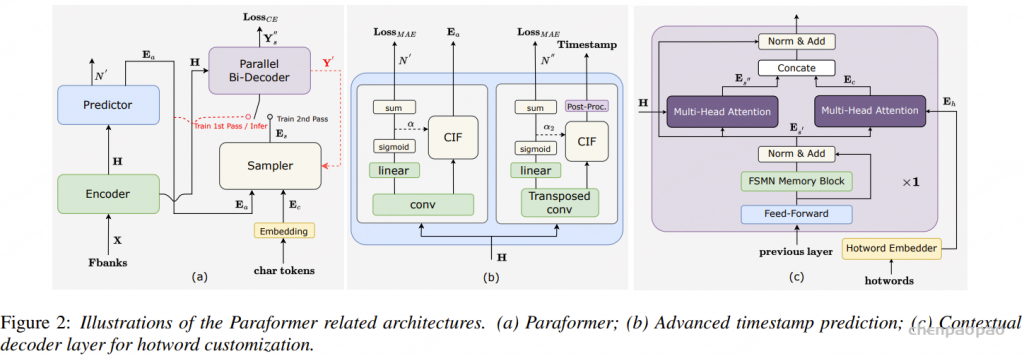
如图2(a)所示。Paraformer是一个单步非自回归(NAR)模型,结合了基于语言模型的快速采样模块,以增强NAR解码器捕捉标记之间依赖关系的能力。
Paraformer由两个核心模块组成:预测器和采样器。预测器模块用于生成声学嵌入,捕捉输入语音信号中的信息。在训练过程中,采样器模块通过随机替换标记到声学嵌入中,结合目标嵌入生成语义嵌入。这种方法使得模型能够捕捉不同标记之间的相互依赖关系,并提高模型的整体性能。然而,在推理过程中,采样器模块处于非激活状态,声学嵌入仅通过单次传递输出最终预测结果。这种方法确保了更快的推理时间和更低的延迟。
Timestamp Predictor:
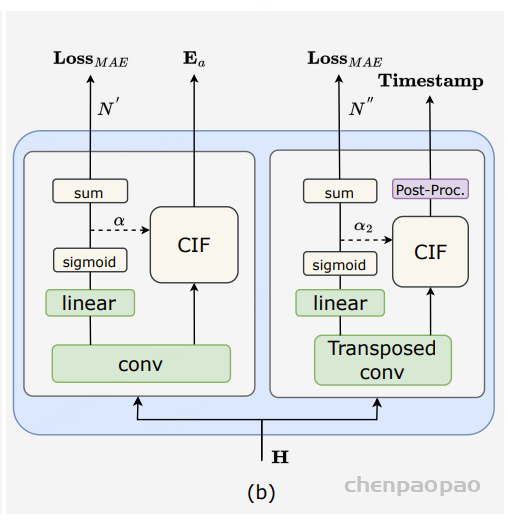
准确的时间戳预测是 ASR 系统的关键功能。然而,传统的工业 ASR 系统需要额外的混合模型来进行力对齐 (FA) 以实现时间戳预测 (TP),从而增加计算量和时间成本。FunASR 提供了一个端到端的 ASR 模型,通过重新设计 Paraformer 预测器的结构来实现准确的时间戳预测,如图2 (b) 所示。我们引入了一个转置卷积层和 LSTM 层来对编码器输出进行上采样,并通过后处理 CIF 权重 α2 来生成时间戳。我们将两个fireplaces 之间的帧视为前一个标记的持续时间,并根据α₂标出静音部分。此外,FunASR还发布了一个类似强制对齐的模型TP-Aligner,该模型包括一个较小的编码器和一个时间戳预测器。它接受语音和相应的转录作为输入,以生成时间戳。
我们在AISHELL和60,000小时工业数据上进行了实验,以评估时间戳预测的质量。用于衡量时间戳质量的评估指标是累积平均偏移(AAS)。我们使用了一个包含5,549个手动标记时间戳的测试集,将提供的模型与使用Kaldi训练的FA系统进行时间戳预测性能比较。结果显示,Paraformer-TP在AISHELL上优于FA系统。在工业实验中,我们发现提出的时间戳预测方法在时间戳准确性方面与混合FA系统相当(差距小于10毫秒)。此外,这种单次解决方案对于商业使用非常有价值,因为它有助于减少计算和时间开销。
1. CIF 模块的核心机制:
CIF 模块通过以下步骤实现时间戳预测:
- 权重预测:模型为每一帧预测一个权重 α_t,表示该帧对当前词的贡献程度。
- 累积积分:将连续帧的权重 α_t 累加,直到总和达到预设的阈值 β。
- 触发发射:一旦累积权重达到阈值 β,模型将当前累积的帧级特征 h_t 加权求和,生成一个词级的表示 c_u。
- 重复过程:继续上述过程,直到处理完所有帧,生成完整的词级序列。
这种机制允许模型在不依赖自回归的情况下,确定每个词的边界,实现高效的并行解码。
2. 时间戳的生成:
在 FunASR 中,时间戳的生成过程如下:
- 上采样编码器输出:引入转置卷积层和 LSTM 层,对编码器输出进行上采样,增强时间分辨率。
- 后处理 CIF 权重:通过对 CIF 权重 α2 进行后处理,确定每个词的起止时间。
- 静音部分的标注:根据 α2 的值,标注出静音部分,进一步提升时间戳的准确性。
此外,FunASR 还提供了一个名为 TP-Aligner 的模型,用于在输入语音和对应转写文本的情况下,生成时间戳。
通过 CIF 权重 α 后处理确定词的起止时间
CIF 权重 α 表示每一帧对当前输出 token(如汉字或子词)的贡献程度。在推理过程中,模型会累积连续帧的权重 α_t,直到总和达到或超过一个预设的阈值 β(通常为 1)。此时,模型认为已经收集了足够的信息来生成一个输出 token。
为了确定每个词的起止时间,可以按照以下步骤进行后处理:
- 初始化:设置累积权重 accumulator = 0,记录当前 token 的开始帧 start_frame。
- 遍历帧序列:对于每一帧 t,执行以下操作:
- 将当前帧的权重 α_t 加到 accumulator 上。
- 如果 accumulator < β,继续累积。
- 如果 accumulator ≥ β,记录当前帧 t 作为当前 token 的结束帧 end_frame。
- 将 accumulator 减去 β,设置 start_frame = t + 1,开始下一个 token 的累积。
- 计算时间戳:根据帧率(例如,每帧 10ms),将 start_frame 和 end_frame 转换为时间戳,得到每个词的起止时间。
这种方法允许模型在不依赖自回归的情况下,确定每个词的边界,实现高效的并行解码。
🤫 标注静音部分
静音部分通常对应于 CIF 权重 α 值较低的帧。为了标注静音部分,可以采用以下策略:
- 设定阈值:选择一个合适的阈值(例如 0.01),用于判断帧是否为静音。
- 遍历帧序列:对于每一帧 t,检查其权重 α_t:
- 如果 α_t < 阈值,标记该帧为静音。
- 否则,标记该帧为语音。
- 合并连续静音帧:将连续的静音帧合并为一个静音段,记录其起止时间。
这种方法可以有效地识别语音中的静音部分,对于语音活动检测(VAD)和语音分割等任务具有重要意义。
Monotonic-Aligner 模型:FunASR发布了一个类似强制对齐的模型TP-Aligner,该模型包括一个较小的编码器和一个时间戳预测器。它接受语音和相应的转录作为输入,以生成时间戳。
模型地址:FunASR/funasr/models/monotonic_aligner/model.py
模型权重:https://modelscope.cn/models/iic/speech_timestamp_prediction-v1-16k-offline
本模型为Paraformer-large-长音频版的衍生模型,通过较小参数量的encoder与上采样cif predictor实现了时间戳预测功能,方便用户自由搭建ASR链路中的功能环节。
其核心点主要有:
- Upsample Predictor 模块:在低帧率模型中predictor产生的帧级别权重可能存在预测不稳定的问题,表现为首尾帧出字与连续帧出字,这为基于cif权重的时间戳预测带来了困扰。本模型
- (1) 在predictor的线性层之前引入了反卷积升采样模块与lstm模块,在多倍帧率的情况下预测权重;
- (2) 通过scaled cif对权重进行尺度缩小与平滑,使得cif权重不表现为一个peak而是一段累积过程。通过上述两个操作得到了能用于时间戳预测的帧权重。
- 基于约5w小时工业数据训练的时间戳预测模型,鲁棒性更强,时间戳准确率更高。
TP-Aligner 的工作流程如下:
- 输入处理:接收音频信号和对应的文本转录。
- 特征提取:通过轻量级编码器提取音频的高层次特征。
- 上采样处理:使用转置卷积层和 LSTM 层对编码器输出进行上采样,增强时间分辨率。
- 时间戳预测:结合文本转录信息,预测每个词或子词的起止时间。