选自SIGGRAPH 2023实时渲染领域论文。文章实现了最新的单图像实时合成三维视角的技术。
论文题目:Live 3D Portrait: Real-Time Radiance Fields for Single-Image Portrait View Synthesis
论文链接:https://research.nvidia.com/labs/nxp/lp3d/
本文提出了从单张图像实时推理渲染照片级 3D 表示的单样本方法,该方法给定单张 RGB 输入图像后,编码器直接预测神经辐射场的规范化三平面表示,从而通过体渲染实现 3D 感知的新视图合成。该方法仅使用合成数据进行训练,通过结合基于 Transformer 的编码器和数据增强策略,可以处理现实世界中具有挑战性的输入图像,并且无需任何特殊处理即可逐帧应用于视频。
INTRODUCTION
随着NeRF的提出,三维视觉技术得到快速的发展。三维重建也是非常有意义的工作,其中,单张肖像实现实时三维视角的合成将推动AR、VR、3D远程会议的发展。
基于此,作者提出了该技术的最新方法,该技术的原文表述是infer and render a photorealistic 3D representation from a single unposed image (e.g., face portrait) in real-time.
先来看现有的方法,一般用NeRF+GANs实现3D感知图像生成。其中比较有名的一项技术是EG3D,EG3D的提出者也是本论文的共同作者之一,本文的工作是在EG3D的基础上展开的。
EG3D提出了一种高效的三平面3D表示(triplane 3D representation)(具体细节会在后续给出),并且能够达到与2D GANs相同的实时渲染质量。训练完成后,测试时微调(test-time fine tuning)完成单图像三维重建。但这种方法会有一些问题:
- NeRF的训练通常需要优化目标(careful optimization objectives)和3D先验(additional 3D priors)
- 测试时优化需要准确的相机姿态作为输入或优化相机姿态
- 上述两点优化时耗时的,限制了实时应用
与以往重复使用预训练的generator不同,本篇论文训练了一个端到端的编码器(encoder end-to-end)用于直接从单个输入图像预测三平面3D特征。与以往依赖于多视图真实图像的采集相比,本文不需要获取真实图像,也不需要PBR(physically-based rendering)绘制那样耗时。相反,作者使用预训练的3D GAN生成的多视图一致的合成数据来监督三平面编码器,以便进行新视图合成,再结合数据增强策略和基于Transformer的编码器搭建好模型。在文章中作者展示了对人脸和猫脸三维重建的结果,但作者表示任何3D感知图像generator适用的类别,该模型同样适用。
概括下文章的工作贡献:
- 提出了一种前馈编码器模型,直接从输入图像推断三平面3D表示。不需要测试时优化。
- 提出了一种新的策略,仅使用从预训练的3D感知图像生成器生成的合成数据
- 结合基于Transformer的编码器和实时增强策略,该方法可以处理具有挑战性的输入图像。
2. RELATED WORK
2.1 Light Fields and Image-Based Rendering
传统的方法要么需要许多视图样本,要么需要光场相机作为训练数据。最近提出的NeRF结合3D隐式表示,运用体渲染的方式合成视图,但仍需要大量输入照片。
2.2 Few-shot novel view synthesis
最近一些扩展NeRF的工作用3D隐式表示完成了单图像合成,用到3D卷积、Transformers 等方法。但是这些方法都不是实时生成新视图的,并且都需要多视图图像来训练模型。而作者的方法只需要从预先训练的3D GAN生成的合成图像,这种3D GAN是由单视图图像的集合训练的。
2.3 Learning with synthetic data
当没有基准真实数据(ground truth data )时,合成数据为训练深度学习模型提供了有用的监督。这往往还需要额外的步骤来适应真实图像。
2.4 3D-aware portrait generation and manipulation
最近,3D感知图像生成方法开始解决从单视图2D图像集合中无条件生成逼真的3D表示的问题。结合神经体积渲染(neural volumetric rendering)和生成对抗网络(GANs),最新的3D GAN方法能够生成高分辨率多视图一致图像。作者采用EG3D 的三平面3D表示,实现单视图新视图合成。
2.5 3D GAN inversion
GAN inversion在2D领域取得很大进展,现有的3D GAN inversion方法将给定的图像投影到预训练的StyleGAN2 latent space上,并且在测试时需要摄像机姿态( approximate camera pose )和生成器权重微调( generator weight tuning),以重建域外输入图像。与同时期的工作不同,作者的前馈编码器将未定位的图像作为输入,并且不需要针对摄像机姿态的测试时优化。
2.6 Talking-head generators
给出单个目标肖像和驱动视频,这种Talking-head生成方法主要通过视频数据集训练,侧重于通过操纵2D肖像中的头像姿势和表情来生成talking-head视频。因此,这种方法不预测视点渲染的体积表示和三维几何信息。所以不予比较。
3. PRELIMINARIES: TRIPLANE-BASED 3D GAN
NeRF采用完全隐式的表示,使用神经网络来表示整个三维空间的辐射场,但计算往往需要花费大量时间。首先,对前沿的3D GAN方法EG3D进行概述。EG3D从单视图图像集合和相应的噪声相机姿势中学习3D感知图像生成,EG3D使用混合三平面表示来调节神经体积渲染过程,其中三个典型平面 ��,��,�� 都存储了三个2D特征网格 (feature grids)。使用StyleGAN2生成器,EG3D将噪声向量和相机姿势映射到三平面表示 �∈R256×256×96,对应于3个轴对齐的平面,每个平面具有32个通道。这些特征调节神经体积渲染。
greater detail for equal capacity.

简而言之,将特征存储在正交的三平面(triplane)表示中,通过特征值叠加计算出特定空间点的颜色、体积密度,通过NeRF进行训练,训练得到的参数也保存在三平面表示中。
4. METHOD
作者的目标是将EG3D生成模型的信息提炼到一个前馈编码器的pipline中,这可以直接将未定位的图像映射到一个规范的三平面3D表示,这里的规范表示,对于人脸,头部的中心是原点。该pipline仅需要单次前馈网络传递,从而避免了花销大的 GAN inversion过程,同时允许实时重新渲染输入的任意视点。
作者的工作主要集中在图像到三平面编码器和相关的合成训练方法上,使用EG3D的MLP体积渲染器和超分辨率架构,端到端地训练所有组件。下图是整个模型的推理和训练部分,是文章的重点。
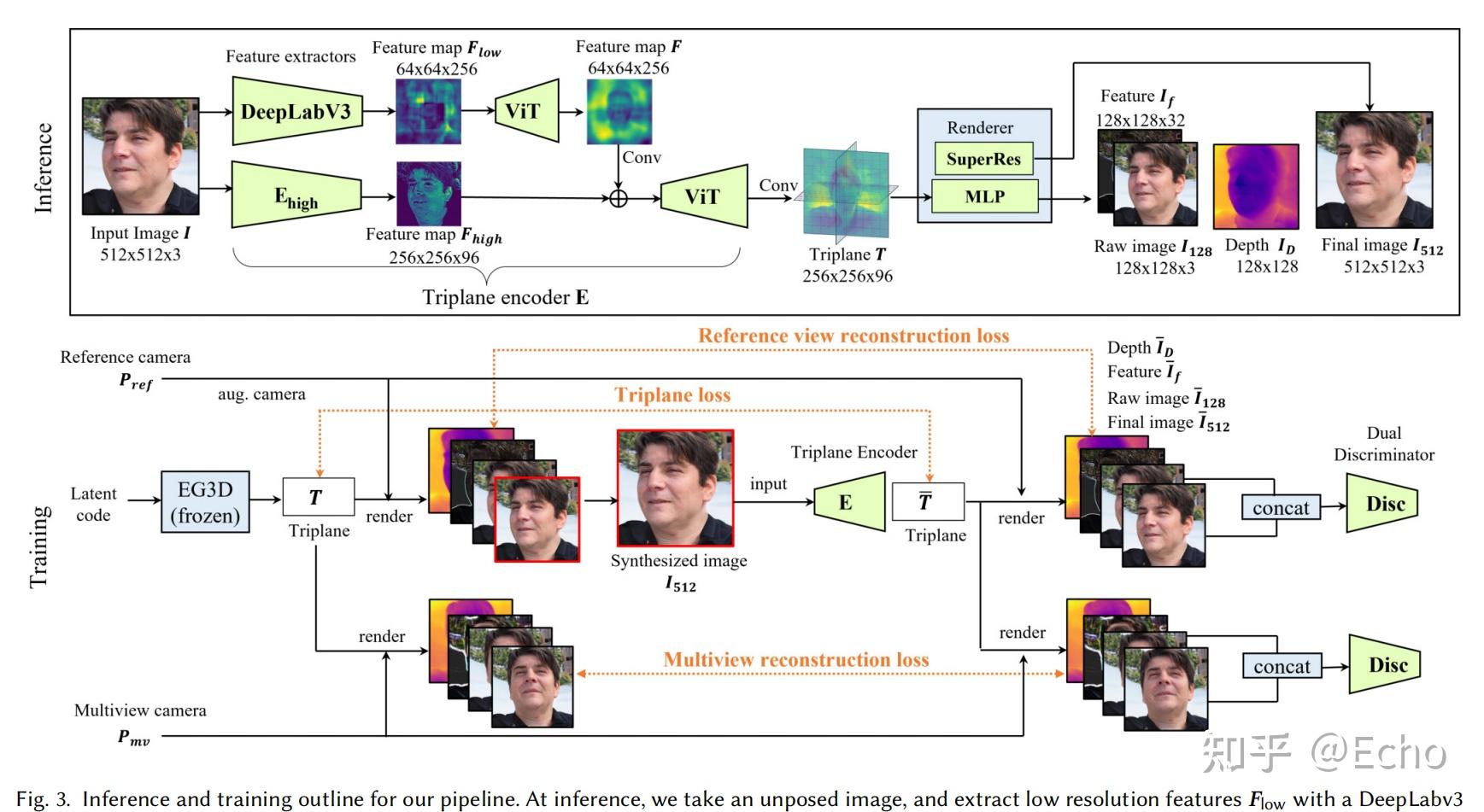
我们的目标是将训练好的 EG3D 生成模型知识蒸馏至前馈编码管线,该管线只需一次前馈网络传播即可将单张图像直接映射为规范的三平面 3D 表示,同时允许对输入在自由视角下进行实时渲染。我们的贡献集中于图像到三平面编码器和相关的合成数据训练方法。我们使用 EG3D 中的 MLP 体渲染器和超分辨率架构,并对所有组件进行端到端的训练。