给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。
candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。
对于给定的输入,保证和为 target 的不同组合数少于 150 个。
示例 1:
输入:candidates = [2,3,6,7], target = 7
输出:[[2,2,3],[7]]
解释:
2 和 3 可以形成一组候选,2 + 2 + 3 = 7 。注意 2 可以使用多次。
7 也是一个候选, 7 = 7 。
仅有这两种组合。
示例 2:
输入: candidates = [2,3,5], target = 8
输出: [[2,2,2,2],[2,3,3],[3,5]]
示例 3:
输入: candidates = [2], target = 1
输出: []
示例 4:
输入: candidates = [1], target = 1
输出: [[1]]
示例 5:
输入: candidates = [1], target = 2
输出: [[1,1]]
提示:
1 <= candidates.length <= 301 <= candidates[i] <= 200candidate 中的每个元素都 互不相同1 <= target <= 500
初次尝试:
# @lc app=leetcode.cn id=39 lang=python3
#
# [39] 组合总和
#
# @lc code=start
class Solution:
def combinationSum(self,candidates, target: int):
nums=list()
nums.append(-1)
length=len(candidates)
rev=[target-i for i in candidates]
nums.extend([target-i for i in candidates])
while [i for i in rev if i>=min(candidates)]!=[]:
mid=list()
for i in rev:
if i<=0:
mid.extend([-1]*length)
nums.extend([-1]*length)
continue
else:
mid.extend([i-j for j in candidates])
nums.extend([i-j for j in candidates])
rev=mid
result=list()
mids=list()
for i in range(1,len(nums)):
if nums[i]!=0:
continue
else:
j=i
while 1:
if j<=length:
mids.append(candidates[j-1])
mids.sort()
print(mids)
if mids not in result :
result.append(mids)
break
elif j//length==j/length:
j=int((j-length)/length)
mids.append(candidates[-1])
else:
mids.append(candidates[j-(j//length)*length-1])
j=int(j//length)
mids=[]
return result
# @lc code=end
显示超时了…..
其实大致反方向对的,但是有些地方不太正确
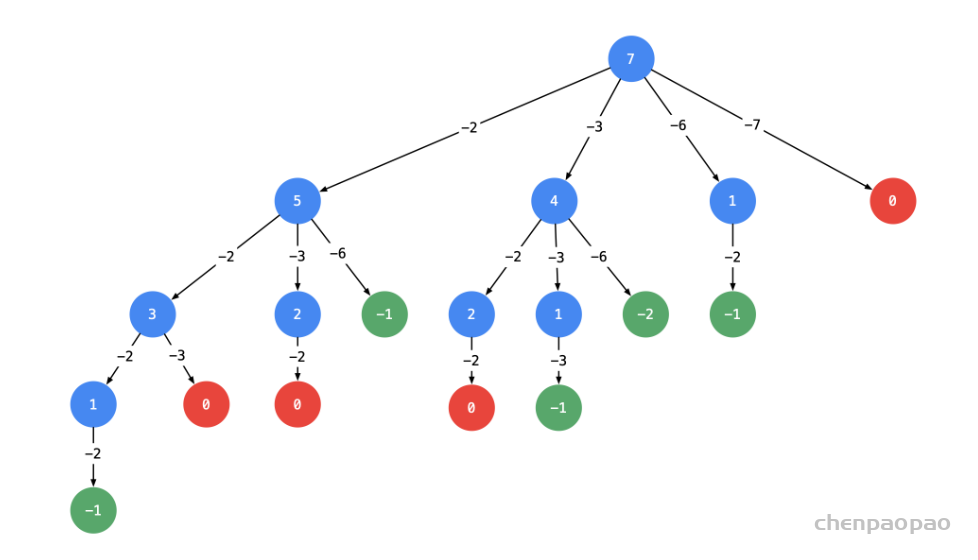
尝试用回溯的方法(递归调用)
from typing import List
class Solution:
def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:
def dfs(candidates, begin, size, path, res, target):
if target < 0:
return
if target == 0:
res.append(path)
return
for index in range(begin, size):
dfs(candidates, index, size, path + [candidates[index]], res, target - candidates[index])
size = len(candidates)
if size == 0:
return []
path = []
res = []
dfs(candidates, 0, size, path, res, target)
return res
剪枝提速
- 根据上面画树形图的经验,如果
target 减去一个数得到负数,那么减去一个更大的树依然是负数,同样搜索不到结果。基于这个想法,我们可以对输入数组进行排序,添加相关逻辑达到进一步剪枝的目的; - 排序是为了提高搜索速度,对于解决这个问题来说非必要。但是搜索问题一般复杂度较高,能剪枝就尽量剪枝。
from typing import List
class Solution:
def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:
def dfs(candidates, begin, size, path, res, target):
if target == 0:
res.append(path)
return
for index in range(begin, size):
residue = target - candidates[index]
#
剪枝提速
if residue < 0:
break
dfs(candidates, index, size, path + [candidates[index]], res, residue)
size = len(candidates)
if size == 0:
return []
candidates.sort()
path = []
res = []
dfs(candidates, 0, size, path, res, target)
return res